REVEN v2 - User documentation
Welcome, this is the starting point of REVEN v2's user documentation. It will guide you through:
- Installing REVEN v2.
- Managing VMs and RE scenarios with the Project Manager.
- Analyzing RE scenarios in the Axion GUI.
- Automating analysis using the Python API.
- Automatic recording cookbooks provide recipes for performing automatic records using REVEN v2.
- Using the integration with WinDbg.
You can also see What's new in the latest release.
Please send any request or comment to support@tetrane.com
What's new?
REVEN 2.9.0 contains a new set of features, improvements and fixes.
- Packages and Compatibility information
- Features, improvements and fixes
- Upgrading from REVEN 2.x
- Known issues and limitations
Packages and Compatibility information
REVEN is available in two packages:
- REVEN Archive to install on Debian 10 Buster amd64
- Docker Image installable on any Linux amd64
- AppImage installable on any Linux amd64
See also this version's compatibility information.
Archive content
This archive shipment consists of an archive file reven-2.9.0.tar.gz with the following content:
reven-2.9.0.tar.gz: full REVEN archive containing the Project Manager, server, clients and their dependenciesREADME.pdf: document containing installation guidelines for REVEN v2README.md: text version ofREADME.pdfdoc/: directory containing text version of the documentationexamples/: directory containing various Python API examplesinstall.sh: script to run as root to install the dependenciesstart.sh: script to run as REVEN user to start the REVEN Project Managerstop.sh: script to stop the running REVEN Project Managersettings.py: the Project Manager settings
python-doc: directory containing the Python API reference in HTML formattools: directory containing various downloadable tools and subpackages:debian_upgrade: helper scripts for the Debian upgrade procedureREVEN-2.9.0-python3.7-debian-buster.tar.gz: Python 3.7 Debian Buster amd64 Python API packageREVEN-2.9.0-python3.7-windows.zip: Python 3.7 Windows 10 64-bit Python API packageREVEN-2.9.0-windows-lightener.zip: An utility that makes Windows VMs lighter to ease recording with REVEN.REVEN-2.9.0-asm-stub-utility.zip: Small library that encapsulates in C functions the ASM instructions used to start/stop records from the guest.REVEN-2.9.0-rvn-kd-bridge.zip: Windows utility to connect WinDbg to a REVEN server.
third-parties: directory containing plugins for third-party tools:REVEN-2.9.0-third-parties-volatility-plugin.zip: A REVEN plugin for volatility
Supported installation environments
Starting with REVEN 2.8.0, the supported installation environment for the REVEN Project Manager and Axion is Debian 10 Buster amd64. For the REVEN v2 Python API, the supported installation environments are Debian 10 Buster amd64 and Windows 10 64-bit. For the REVEN Kd Bridge, the supported installation environment is Windows 10 64-bit.
Docker content
This docker shipment consists of an archive file reven-2.9.0.tar.gz with the following content:
reven-2.9.0-docker.tar.xz: full REVEN docker containing the Project Manager, server, clients and their dependenciesdebian_upgrade: helper scripts for the Debian upgrade procedureREADME.pdf: document containing installation guidelines for the docker imageREADME.md: text version ofREADME.pdfreven2:2.9.0.docker: docker imagerun.sh: wrapper script to launch and stop REVEN.
Supported installation environments
While the system prerequisites to install the archive REVEN package is Debian 10 Buster amd64, this docker package can be installed to run REVEN on any Linux distribution.
AppImage content
The AppImage shipment consists of a file v2.8.1.ai that can be used to run the Axion GUI.
Supported installation environments
While the system prerequisite to install the archive REVEN package is Debian 10 Buster amd64, this AppImage package can be used to run the Axion GUI on any Linux distribution or on Windows 10.
Compatibility information
VM Snapshots
Snapshots that were prepared in a version before 2.7 must be prepared again to update their filesystem.
A snapshot must be prepared for the automatic binary recording to be available on that snapshot and to replay the OSSI feature in a scenario associated to that snapshot.
To update the filesystem of a snapshot, perform the following actions:
- Open the Project Manager
- Go to the VM Manager tab
- Click the name of the snapshot that you wish to prepare again (snapshots that must be prepared anew are marked as incompatible with a red dashed circle icon).
- In the snapshot page, click the Update button.
Bookmarks
Due to how bookmarks are now stored server-side, bookmark files (*.rbm) cannot be used directly in version 2.5 or superior.
You can use the import_bookmarks.py script (in the Download page of the Project Manager) to import the legacy rbm
files.
Resource compatibility
2.7
The following resource replayed in a version before 2.7 is deprecated and should be deleted:
Fast Search/Binary Ranges
To benefit from the Filters and Fast Search features in version 2.7 and superior, the new OSSI Ranges resource must be
replayed:
Fast Search/OSSI Ranges, orFilters/OSSI Ranges
In order to delete deprecated resources and generate new resources, perform the following actions:
- Open the Project Manager
- Go to the Scenario Manager tab
- Click the Update button on the lines corresponding to the names of the scenario you want to update.
2.3
The following resources replayed in a version before 2.3 must be deleted and replayed:
Light OSSI/kernel_descriptionBacktrace/stack_eventsFast Search/binary_ranges
In order to do so:
- Open the Project Manager
- Click the Scenario Manager tab
- Click the name of the scenario you want to replay (scenarios with outdated resources are indicated by red and orange dots next to the scenario status)
- Click Replay
- Delete the resources, select them for replay and click replay.
General compatibility information
-
This version is backward compatible with artifacts from previous 2.x versions such as VMs, VM snapshots, scenario recordings and resources not listed above.
-
Scenarios recorded with version 2.6 or later cannot be replayed with a version of REVEN prior to 2.6.
-
Following a bugfix, should you decide to replay pre-2.6 trace and memory history in version 2.6 or superior, transition numbers will be different after the replay. For this case, we provide a script (to run after replaying the trace and memory history) that updates bookmarks you would have set on the scenario before upgrading. You should run this script if you notice that the bookmarks of a scenario are no longer at the correct location after upgrading and replaying the trace and memory history. We recommend you backup the
bookmarks.sqlitefile in theUserDatadirectory of your scenario before running this script. The script can be downloaded from the "DOWNLOADS" page of the Project Manager, in the "Python API - Analyze" example section. -
When replaying either the trace or the memory history for a QEMU scenario recorded pre-2.2.0, take care to replay both the trace and the memory history: due to a bug fix, traces may have their number of transitions increased by 1, or a modified last context.
-
Live QEMU snapshots created in a version before 2.1.0-beta may exhibit an undesirable mouse cursor behavior where the mouse cursor of the guest is displayed at a different position than the actual mouse cursor from the controlling host. Affected live snapshots must be removed and created again from a running VM.
2.9.0
Highlights
REVEN version 2.9 is packed with new features, with a focus on providing the users with more trace navigation and memory analysis handles in the Axion GUI.
Here are some highlights:
-
Memory Watchers in Axion GUI: The GUI now allows to create Memory Watchers, that will display the value of a range of memory at all times while browsing a REVEN scenario.
-
Markers of a transition's location in the trace: To make it easier to tell at a glance where a particular transition falls in the scenario, hovering a transition in any widget now displays its position in the time. Moreover, the transitions displayed in widgets now sport an icon indicating their position relative to the currently selected transition.
-
Debugger controls with step out and step over navigation in Axion GUI:
Step out/Step overbuttons and their corresponding shortcuts allow to quickly find the exit of a function, or to skip over a call in a single action. Due to REVEN's timeless nature, it is of course possible to step out/step over backward. -
Step out and step over are also available in the Python API: The new methods
Transition.step_outandTransition.step_overbring this capability to the API where it can be used for automation. For example,step_outallows to easily find the return value of a function you're in. -
New sample scripts and notebooks:
detect_data_race.ipynb: demonstrates how to use the API to detect data races in programs whose synchronization would depend on critical sections.threadsync.py: traces calls to Windows synchronization APIs such asEnterCriticalSection,WakeConditionVariableorReleaseMutex.export_bookmarks.ipynbandbk2bp.ipynb: demonstrates how to use the bookmark API to generate a report in HTML or markdown or to generate breakpoints that can be imported into WinDbg.- All sample scripts can now be browsed in the documentation.
Improvements
REVEN
- High-level OS Specific Information (OSSI) has been enhanced:
- In Windows scenarios, REVEN now presents private symbols from PDBs, as well as symbols from PDB modules. Besides, the performance of PDB parsing has been improved by up to 400%, which translates in a shorter waiting time when loading transitions for the first time in the trace in Axion GUI or the Python API.
- In Linux scenarios, REVEN now loads symbols from debug binaries if available at the standard locations looked up by GDB (such as
/usr/lib/debug).
Project Manager
- In Linux scenarios, the debug binaries are now extracted when replaying the Light Filesystem resource.
Analysis Python API
- The
reven2.Trace.memory_accessesmethod now supports fetching memory accesses on the entire trace or on a range of transitions regardless of the address of the memory access. Concretely, this means that theaddressandsizeparameters of this method are now optional.
Axion
- The Calltree view now displays bookmark icons next to entries corresponding to a bookmarked transition.
- Hexdump views can now be renamed so that their identification is easier during the analysis. To rename a Hexdump, right-click on it, then choose "rename".
- You can now select which Hexdump view is "active" by clicking the corresponding button in the widget. The active Hexdump is the one which is used when a new address is selected for display. If no Hexdump is active, selecting an address will display it in a new one.
- Shortcut management:
- Shortcut conflicts are now displayed in the shortcut editor.
- A modal dialog now warns user upon inputting a shortcut that is associated to multiple actions.
- Axion no longer saves or loads shortcuts that are the same as the default in the settings. This reduces the probability of a shortcut conflict when upgrading Axion.
Fixed issues
REVEN
- The taint now propagates correctly through the
bswapinstruction.
Project Manager
- Compressed Linux kernel modules files were not copied during the light filesystem extraction of a scenario.
Axion
- Calltree view: The binary name for the root node of the calltree was sometimes mistakenly reported as
unknown. - Calltree view: The current transition display (red line) is now displayed at the correct location in the following situations:
- when the children of the last call node also have children nodes,
- when the calltree view has been "locked" by clicking the lock button.
- Closing Axion with a
SIGINTorSIGTERMsignal is now considered like a normal exit. This allows in particular to save Axion's settings when an Axion session is stopped from the Project Manager.
Analysis Python API
- Some calls to the
preview.project_managerAPI could spuriously fail with aConnectionError, especially when using a high-latency connection. - Python dependencies of example scripts are now distributed along
reven2, which makes use of these scripts easier, especially in air-gapped networks.
Analysis Python API Compatibility Notes
- The
Stack.backtracemethod and theBackTraceclass have been deprecated and are scheduled for removal in version 2.10. Usestrordisplayon aStackinstance to display a backtrace.
Upgrading from previous REVEN versions
Upgrading from REVEN<=2.7.1 to >=2.8.0
Please follow the dedicated guide, as this upgrade requires a Debian upgrade.
Upgrading from REVEN 2.x
To upgrade from a previous REVEN v2.x version, please follow the following steps:
-
Stop the running REVEN Project Manager by calling the
stop.shscript from the directory of the REVEN 2.x installation being upgraded. -
Extract the archive to a new directory, as described in the Installation page.
-
Run
install.shas an administrator to update system dependencies. -
Upon running
start.shfor the first time, you will be provided with the choice to migrate your scenarios from your existing REVEN 2.x installations. -
If upgrading from REVEN < 2.4, you will be prompted for your license key on the first start of the Project Manager. You should have received your license key by email. If not, please contact support.
Upgrading from REVEN v1.x
To upgrade from a REVEN v1.x version, you will need to perform a fresh installation by following the installation instructions.
Migration guide from Stretch to Buster
This guide will help you upgrade your REVEN installation, whether based on a regular archive or a Docker image, from any version running on Debian Stretch (<=2.7.1) to any version running on Debian Buster (>=2.8.0). For the sake of simplicity, it will assume and present commands for a 2.7.1 to 2.8.0 migration.
A manual operation is needed in the process because of the transition from PostgreSQL 9.6 to PostgreSQL 11.
There will be three main steps: dumping your database, upgrading your system to Buster, then restoring the database.
For non-Docker users
This section is for users that use the regular REVEN archive, not the Docker image. If you use the Docker image, chances are that you even don't run Debian Stretch in the first place, so please read the next section.
Preparing the files
Please be sure that you have the dump.sh and restore.sh scripts accessible from
the user running REVEN.
These scripts are available both from the REVEN package you downloaded (in the
tools/debian_upgrade folder of the standard package, or directly in the
debian_upgrade folder in the Docker package), or from
Github.
Dumping the database
In the procedure below, we assume that the QUASAR_ROOT folder is the default
~/Reven2. Should you have customized the QUASAR_ROOT setting, please
adapt the procedure accordingly.
IMPORTANT: These steps are to be performed before the migration while you are still running Debian Stretch and REVEN 2.7.1:
- Open a shell with the user that runs REVEN.
- Go to your 2.7.1 REVEN installation folder (the one where you extracted your 2.7.1 REVEN package to).
- Run
./start.shto start everything. - Run
./dump.sh. Check that adump-2.7.1.sqlfile was created in your~/Reven2folder. - Run
./stop.shto stop everything. - (Optional but recommended) Also make an external backup of your
~/Reven2folder, so that even if something goes wrong, you will be able to restore your data.
You can repeat those steps any time you want if you thought of some last-minute changes to your REVEN data. Just be sure to have a dump of the latest state of the database before the OS upgrade.
Upgrading your system to Buster
A comprehensive guide is provided by Debian https://wiki.debian.org/DebianUpgrade and is the most up to date and trustworthy place to find documentation on Debian upgrades.
IMPORTANT: The kvm group of your Stretch installation may cause issues
during the upgrade process. To avoid them, please delete the group before
upgrading. The group will be recreated later automatically: sudo groupdel kvm.
If you forgot this step and encounter the following error during upgrade:
The group 'kvm' already exists and is not a system group. Exiting.
simply delete the kvm group at that moment, and run sudo apt install -f to
let apt configure the failed packages, then continue the upgrade procedure as
usual.
Restoring the database
These steps are performed after the migration while you are now running Debian Buster and REVEN 2.8.0.
In the procedure below, we assume that the QUASAR_ROOT folder is the default
~/Reven2. Should you have customized the QUASAR_ROOT setting, please
adapt the procedure accordingly.
- Open a shell with the user that runs REVEN.
- Go to your REVEN installation folder.
- Run
./install.shto ensure all the system dependencies are installed. - Run
./start.sha first time. - If you need to restore parameters into the
settings.pyconfiguration file, now is the right time to do it. - Now we need to get the right data at the right place, including the database
to migrate. The easiest way to do that is to attempt to start REVEN, which
will end with an expected failure since the database was not restored
yet.
Run./start.sha second time.
Use the script interface to migrate your old data to the new REVEN version. - The previous step should leave you with an error message that looks like the
following:
The part you are interested in is after theA process (postgres) failed to start (cmd: '/usr/lib/postgresql/11/bin/postgres -D /home/<user>/Reven2/2.8.0/db-2.8.0.psql -k /tmp/tetrane-1000 -p 37221')-Dargument. This is the path to your PostgreSQL database that needs migration. - Run the following, of course adapting the
<user>part to your situation:./restore.sh /home/<user>/Reven2/2.8.0/db-2.8.0.psql /home/<user>/Reven2/dump-2.7.1.sql - Finally, run
./start.shone last time. As you have already handled the migration in step (6), you need to keep using your existing data, so answernowhen the script asks if it should overwrite the data directory.
The REVEN Project Manager is now up and running. Enjoy!
If you made any mistake during one of these steps, don't panic. You can repeat them over and over, until you have restored the right database in your REVEN Project Manager.
For Docker users
This section is for users that use the REVEN Docker image. If you don't run REVEN through Docker, please read the previous section.
Preparing the files
Please be sure that you have the dump.sh and restore.sh migration scripts
accessible from the user running REVEN. These scripts are available in the
debian_upgrade folder in the Docker package, or from
Github.
As the user running REVEN is inside the running container, the best place for
you to put the dump.sh and restore.sh migration scripts is probably your
REVEN2_PATH that defaults to ~/Reven2 on your host.
Inside the container, the REVEN2_PATH will be accessible in the /Reven2
directory and the REVEN installation folder in /reven.
Dumping the database
These steps are performed using the Stretch-based REVEN container (<=2.7.1).
- Ensure your REVEN container is running:
./run.sh. - Get a shell inside the running container:
docker exec -it <username>-reven su reven - Make the dump:
/Reven2/dump.sh - Exit the container:
exit - Stop the container:
./run.sh
You should now have a dump-2.7.1.sql file in your ~/Reven2 directory.
You can repeat those steps any time you want if you thought of some last-minute changes to your REVEN data. Just be sure to have a dump of the latest state of the database before the REVEN upgrade.
Upgrading your REVEN version
Just as usual, download a REVEN 2.8.0 Docker package and extract it in the
directory of your choice, for example using tar xvf <package>.
Restoring the database
These steps are performed after the extraction of the REVEN 2.8.0 Docker package.
In the procedure below, we assume that the REVEN2_PATH folder defined in
the run.sh script is the default ~/Reven2. Should you have
customized the REVEN2_PATH setting, please adapt the procedure accordingly.
- We first need to get the right data at the right place, including the
database to migrate. The easiest way to do that is to attempt to start the
REVEN container.
This will end with an expected failure since the database was not restored yet.
Run./run.sha first time.
Use the script interface to migrate your old data to the new REVEN version. - The previous step should leave you with an error message that looks like the
following:
The part you are interested in is after theA process (postgres) failed to start (cmd: '/usr/lib/postgresql/11/bin/postgres -D /Reven2/2.8.0/db-2.8.0.psql -k /tmp/tetrane-1000 -p 37221')-Dargument. This is the path to your PostgreSQL database that needs migration. - Stop the container:
./run.sh. - Run a temporary container to perform the migration:
docker run -it --rm --entrypoint bash -v ~/Reven2:/Reven2 tetrane/reven2:2.8.0-enterprise -c 'su reven'
Of course, adapt the Docker image name (tetrane/reven2:2.8.0-enterprise) to the one you are using.- Run the restore process:
/Reven2/restore.sh /Reven2/2.8.0/db-2.8.0.psql /Reven2/dump-2.7.1.sql - You can now close the temporary container:
exit.
- Run the restore process:
- Run a final
./run.sh.
The REVEN Project Manager is now up and running. Enjoy!
If you made any mistake during one of these steps, don't panic. You can repeat them over and over, until you have restored the right database in your REVEN Project Manager.
Known issues and limitations
These are items we want to let you know about:
-
Incomplete support of OSSI for Windows 10 version 21H1 VMs: The OSSI cannot find the
ntoskrnl.exebinary in Windows 10 version 21H1 scenarios. This has the following consequences for these scenarios:- All portions of the trace executing the
ntoskrnl.exebinary report an unknown location to Axion and the API. - WinDbg interoperability does not work on these scenarios.
- Scripts that make use of
ntoskrnl.exe(such asdata_race_detection.ipynb) will not work on these scenarios.
- All portions of the trace executing the
-
The Axion layout is not fully saved: When restarting Axion, changes made to the size of the left and right columns of widgets may not be saved after updating Axion. If this happens to you, then remove the
$HOME/.config/tetrane/reven2.conffile. The layout will be reset to the default on the next Axion startup, but it will be saved as expected for future launches of Axion. -
In case Axion is unresponsive on some scenarios, try to delete the strings resource and restart the REVEN server on this scenario.
-
Only a single taint can run concurrently per REVEN scenario: currently, starting a second taint, even from a different Axion or the Python API, will cancel the first running taint. Besides, if two clients (such as two Axion sessions) are involved, the first client may display mixed taint results.
-
If a taint generates many changes, the taint widget may slow down Axion. Cancelling the current taint operation will revert Axion's slowdown.
-
When using the auto-record functionality, the replay operation may fail at the start of the trace with the following error:
detect_infinite_loops: Assertion 'false' failed. Performing a new scenario recording usually fixes the issue.
Previous versions
In this section, you can find the changes to previous versions of REVEN:
2.8.2
REVEN 2.8.2 is a bugfix release. Upgrading from REVEN 2.8.1 is recommended.
- If upgrading from 2.7.1 or earlier, it is mandatory to read the release notes for version 2.8.0.
- If upgrading from 2.6.0 or earlier, it is recommended to read the release notes for version 2.7.0.
Fixed issues
Axion GUI
- In the Calltree view, the current transition indicator displayed as a red horizontal line could be wrong when folding the oldest parent.
- The Calltree view could cause unnecessary CPU usage.
- In the tutorial, Next/Prev buttons would not work in some cases.
Strings
- In the Strings resource, some strings could contain garbage characters.
Analysis of Linux systems
- The Framebuffer view could be wrong for some Linux scenarios recorded in graphical mode (X or Wayland server...).
- Symbols could be wrong for binaries whose lowest LOAD section was not executable.
- Kernel description generation would fail in some cases, leading to unavailable OSSI information.
2.8.1
REVEN 2.8.1 is a bugfix release. Upgrade from REVEN 2.8.0 is recommended.
- If upgrading from 2.7.1 or earlier, it is mandatory to read the release notes for version 2.8.0.
- If upgrading from 2.6.0 or earlier, it is recommended to read the release notes for version 2.7.0.
Fixed issues
- In REVEN v2.8.0, disassembled instructions were displayed without prefix(es) in Axion and the Python API.
2.8.0
Highlights
REVEN version 2.8 is packed with new features, still with a strong focus on providing you with a "bird's eye view" over a trace, so that you can get important information about what happens in a scenario at a glance! Here are some highlights:
-
Call Tree view in Axion GUI: the GUI now proposes a new Call Tree view that provides users with far more semantic information about what is going on in the trace. Navigate to one transition and immediately visualize the call history before and after this transition, from there jump to surrounding points of interests.
-
New vulnerability detection notebooks: new Jupyter Notebooks are available to help you detect Buffer Overflow vulnerabilities and Uninitialized Memory vulnerabilities. The notebooks are available in the "Python API - Analyze" examples of the "Download" page of the Project Manager, as well as on our GitHub.
Important Compatibility Notes
-
REVEN version 2.8 is the first version of REVEN to support Debian Buster and Python 3.7. As a result, support for Debian Stretch and Python 2.7 has been removed. See the migration guide for more information on the upgrade process.
-
REVEN version 2.8 switches from Capstone to Zydis as its disassembler backend. This modifies the result of the
reven2.trace.Instruction.mnemonicand thereven2.trace.Instruction.operandsmethods, as well as the display of some instructions in Axion.For example, the instruction
xmmword ptr [rdi + rcx]is now rendered asxmmword ptr [rdi+rcx*1], the instructionrep movsq qword ptr [rdi], qword ptr [rsi]is now rendered asrep movsq(the operands are implicit), or the instructioncmpltps xmm1, xmm0is now rendered ascmpps xmm1, xmm0, 0x1(fixing the mnemonic and the operands). -
The behavior of the
Tainter.simple_taintandTaintResultView.filter_by_context_rangefunctions has been modified in the way theto_contextparameter is handled. Previously, the taint would not propagate through theTransitionright before theto_contextparameter. With this change, it is now the case. This means that a simple taint between contextcand contextc + 1will now propagate through the transition between contextcand its successor context, whereas before it would propagate through no context at all.
Improvements
REVEN
- Taint performance has been improved up to x4 in some workloads (long taint with lots of tainted memory benefit most from the improvement)
- In the Python API
Taint.accessesslicer, more instructions are reported as "accessed":- When the conditional flag is tainted in a conditional move or jump
- When a tainted register is used to dereference memory
- Changed REVEN's disassembler backend from Capstone to Zydis, yielding runtime improvements in performance and correctness.
- In the Enterprise edition, it is now possible to start and stop recording using the ASM stub, even when performing an automatic binary record. This allows for more flexiblity in the record options.
Analysis Python API
- The accuracy of the
Transition.find_inversemethod has been improved so that it returns the correct transition in more cases. - Added an example script
thread_id.pyto detect the current thread and find the transition where it was created. You can find it in theDownloadpage of the Project Manager. - The standalone Python API Debian package is now easier to use with the addition of a
sourcemescript. Please refer to the installation documentation for more information.
Axion
- The Backtrace view now skips "trampoline" calls by default. Trampoline calls are calls that immediately call another function selected dynamically by an indirect jump. It is desirable to skip them, since they muddle the backtrace and don't add any useful information.
- The accuracy of the "%" (find inverse) plugin has been improved so that it jumps to the correct transition in more cases.
- You can now choose the numeric base in which to display the register values in the CPU view.
- Displaying symbols in the Taint view is now optional.
VirtualBox
- VirtualBox is now shipped in version to 6.1.18, which brings all the benefits of VirtualBox 6 to REVEN, such as the major rework of the user interface and the support of host Linux kernels up to version 5.10. QEMU remains the recommended way to record scenarios for most usages.
Fixed issues
Analysis Python API
TaintResultView.filter_by_context_rangewould raise anAttributeErrorwhen theto_contextparameter wasNone.- The provided
automatic-scenario-creation.pyexample no longer fails attempting to replay the deprecatedbinary_rangesresource. Context.find_register_changecould loop infinitely when invoked in backward.Context.find_register_changecould skip changes depending on the value of the technicalfetch_countparameter.Context.find_register_changewould mistakenly raiseAttributeErrorwhen itsto_contextparameter wasNone.
Project Manager
- When recording a QEMU VM with UEFI enabled, the UEFI boot option is now passed correctly when replaying.
- External processes launched by the Project Manager are correctly terminated by clicking the various
Stop sessionbuttons. - It was not possible to use OSSI without the kernel description and light filesystem resources. The snapshot filesystem can now be used if the light filesystem is not available.
- The Project Manager would sometimes fail to correctly terminate its subprocesses. This would lead to some zombie processes remaining on the server running the Project Manager, and in some cases would lead to a failure to stop a VM when clicking the "Stop VM" button.
- A superfluous and misleading error was displayed when attempting to replay without being able to delete all the necessary resources.
2.7.1
REVEN 2.7.1 is a bugfix release. Upgrade from REVEN 2.7.0 is recommended.
If upgrading from 2.6.0 or earlier, it is recommended to read the release notes for version 2.7.0.
Fixed issues
- The taint would sometimes crash when run backward. In Axion, the crash could manifest with taint results being unexpectedly cut short, and sometimes all the changes reported in the taint would be prefixed by a warning sign.
- Axion would sometimes crash while browsing the trace with some text selected in the Trace view.
- Creating a live snapshot for a VM with more than 4GB of RAM would sometimes freeze the VM and never end, growing the snapshot file on disk indefinitely.
- Wrong symbols could sometimes be displayed when disconnecting Axion and reconnecting it to another project.
Future compatibility notes
-
Debian 9 (Stretch) is getting old. To provide you with recent software and improve our development process, please note that REVEN 2.7.x versions are the last versions that will run on Debian 9 (Stretch). If you are using the Debian archive of REVEN, you will need to upgrade to a new Debian version to install REVEN 2.8 or superior.
-
Please note that REVEN 2.7.x versions are the last versions that support Python 2.7, which has reached End-of-Life in 2020. Future versions of REVEN will only support Python 3.7 and superior.
Limitations and known issues
- When recording a QEMU VM with UEFI enabled, the UEFI boot option is not passed when replaying.
As a workaround, add
-bios /usr/share/ovmf/OVMF.fdto the replay options when replaying a scenario recorded with a UEFI-enabled VM.
2.7.0
Highlights
REVEN version 2.7 is packed with new features, with a strong focus on providing you with a "bird's eye view" over a trace, so that you can get important information about what happens in a scenario at a glance! Here are some highlights:
-
Filter Widget in Axion: the Axion GUI now proposes a new Filter Widget, that allows you to see at a glance which processes are present in the trace, and specify which ones are of interest to you, as well as which rings you would like to see (user, kernel, or both). The Trace view then reflects which ranges of transitions belong to the specified filter, and allows to browse between these ranges by skipping the filtered out transitions. Please refer to the documentation for more details on filters.
-
Use-after-Free vulnerability detection notebook: this Jupyter Notebook leverages the taint API of REVEN to search for potential Use-after-Free vulnerabilities in a REVEN scenario recorded on a Windows x64 machine. The notebook can be configured to only search for vulnerabilities in some processes/binaries of the trace so as to maximize performance. By default, the notebook supports the user
mallocand the systemExAllocatePoolWithTagallocators, but you can modify the notebook to add more! The notebook is available in the "Python API - Analyze" examples of the "Download" page of the Project Manager, as well as on our GitHub -
File activity report tool: this tool reports the file operations, such as creation, opening, reads and writes, that occur in a REVEN scenario recorded on a Windows x64 machine. The tool is available on our GitHub.
-
Crash quick report tool: this tool detects and reports system crashes and user exceptions that occur in a REVEN scenario. The tool is available in the "Python API - Analyze" examples of the "Download" page of the Project Manager, as well as on our GitHub.
-
ASM stub automatic recording from the Project Manager (Enterprise Edition): you can now automatically start and stop a record when the guest VM executes a specific instruction, directly from the Record page of the Project Manager. For more information about ASM stub recording, please refer to the documentation.
-
Improved Linux OSSI support: for kernels in the supported version range (versions 4.1 to 4.14.9), the OSSI are now automatically generated for 64-bit Linux VMs. This allows you to access e.g. the kernel symbols more easily in a Linux scenario. Please refer to the documentation for more details on OSSI for Linux. Note that process filtering is not available on Linux scenarios at the moment, and due to the way dynamic symbols are called in Linux, the backtrace widget may provide less useful information.
This version introduces changes that will make it necessary to regenerate some resources in order to benefit from all REVEN features in your scenarios. See compatibility information for more information before upgrading.
Improvements
Analysis Python API
- Added the
reven2.RevenServer.scenario_nameto get the name of the current scenario from the API. - The
dump_pcap.pyscript now reports in its standard output the address in memory of each packet.
Project Manager
- Configuring QEMU VMs with 3GB of RAM and more is available in Beta Testing and may still be unstable.
- Preparing a VM snapshot by extracting its filesystem now requires much less space during the process (from 3x the space of the extracted filesystem to as low as 1x), incurs less stress on the I/O, which makes the machine more usable during the process, and also requires less space on disk after extraction. Due to this change, it is required to prepare anew all of your snapshots to benefit from the OSSI in the associated scenarios. See compatibility information for more information before upgrading.
- In the Enterprise Edition, you can now update the outdated resources and clean the deprecated ones in a single click
with the new
Updatebutton that is available next to each scenario in the scenario list of the Project Manager. - You can now access the notebooks of a scenario with a new link in the scenario's description page. Besides, all the notebooks can be accessed with a new link in the footer of each Project Manager page.
Axion
- The Taint widget now displays the symbol corresponding to the transition at which each taint change is performed.
WinDbg integration
- Axion can now be synchronized with WinDbg, so that whenever WinDbg requests a new transition with a debugging command, the same transition is selected in Axion
Fixed issues
REVEN
- The taint would sometimes assign the wrong memory address to a tainted address in basic blocks of instructions when
the block contained
and memory, 0instructions or similar instructions with a "memory desynchronization" warning.
Analysis Python API
TaintAccess.state_beforeandTaintAccess.state_afterwould sometimes raise aStopIterationexception.- Multiple calls to
Taint.simple_taintwould mistakenly share the same taint data.
Project Manager
- It is now possible to upload a VM from disk when running REVEN in a Docker container.
- It is no longer possible to delete resources of a scenario while the corresponding REVEN server is running.
- QEMU not responding would sometimes cause an error on some pages when interacting with a VM.
- When exporting PDBs during a scenario export, PDBs of the CDROM files will be exported too as long as they are in the SYMSTORE.
- Imported resources now correctly report a progress of 100%.
- Attempting to delete a non-existing resource does not cause an error anymore.
- The light filesystem used to be incomplete for Linux scenarios, which could lead to less symbols in imported scenarios.
Axion
- The "prev"/"next" links now display the symbol of the previous/next backtrace switch rather than the symbol of the current transition.
- The status bar is now correctly cleared when the user disconnects from a project.
Future compatibility notes
-
Debian 9 (Stretch) is getting old. To provide you with recent software and improve our development process, please note that this REVEN 2.7 version is the last version that will run on Debian 9 (Stretch). If you are using the Debian archive of REVEN, you will need to upgrade to a new Debian version to install REVEN 2.8 or superior.
-
Please note that this REVEN 2.7 version is the last version that supports Python 2.7, which has reached End-of-Life in 2020. Future versions of REVEN will only support Python 3.7 and superior.
Limitations and known issues
- When recording a QEMU VM with UEFI enabled, the UEFI boot option is not passed when replaying.
As a workaround, add
-bios /usr/share/ovmf/OVMF.fdto the replay options when replaying a scenario recorded with a UEFI-enabled VM.
2.6.0
Highlights
REVEN version 2.6 is packed with new features, from GUI and workflow improvements to ever better third party integration! Here are some highlights:
-
Whole trace search in memory: The new
trace.search.memoryAPI entry allows to look for arbitrary patterns of bytes in the memory accessed throughout the entire trace. -
The WinDbg integration now supports stepping commands, setting breakpoints and going to the next breakpoint: This allows you to use even more of your usual WinDbg workflows with REVEN, and in particular significantly improves how you can browse the REVEN trace from WinDbg. This changes a bit how you can use the integration. Please refer to the documentation for more details.
-
The Taint in the Analysis API now returns the instructions that use tainted data: Before version 2.6, only the instructions that changed which data was tainted could be queried. With this new feature, you can now extract a shorter program, containing only the instructions that are relevant to the tainted data, allowing the taint to act as a slicer. Use the
Taint.accessesmethod to get the list of the instructions that use tainted data. -
A new "ltrace-like" tool is available: for a given binary in a trace, it allows to see all the calls to functions of external binaries, complete with their parameters and return types (when they are known to the system, such as functions documented on the MSDN). Users can also add their own signature to the system for the calls to be recognized. You can find this tool on our Github.
-
Automatic binary recording from the Project Manager (Enterprise Edition): you can now automatically start a record when a binary starts executing, directly from the Record page of the Project Manager. The record stops automatically when the binary either exits or crashes (or if the VM itself crashes). For both Enterprise and Professional editions, the Record page was revamped for the occasion and sports a more reactive and complete interface that includes the improvements introduced by the VM Creation Wizard in version 2.5.0.
Improvements
REVEN
- REVEN can now be used behind a proxy for contacting the license server (Professional Edition), downloading symbols from a symbol server and downloading VMs in the VM wizard. Please refer to the installation documentation for more details.
Analysis Python API
- Add
Context.search_in_memorymethod to perform a search in the virtual memory at a single context. This is the API entry corresponding to thesearch_in_memory.pyscript introduced in version 2.5.0. - Add various helper methods to get the first and last context and transition in a trace.
Axion
- The Bookmark widget now displays the symbol corresponding to the transition at which the bookmark was set.
- Improved reactivity of the Backtrace widget when there are many backtrace items.
- Improved the Hexdump widget:
- The default block size in the Hexdump widget now depends on the current mode: QWORD when in 64-bit, DWORD when in 32-bit.
- The Hexdump widget now keeps the scroll position and current selection when going back and forth in history.
- You can now optionally select with which segment you wish to follow an address from the Hexdump and CPU widgets.
Fixed issues
REVEN
- The QEMU emulator and the PANDA recorder/replayer components have been upgraded. This upgrade fixes some possible segmentation faults while replaying the trace. Note that scenarios recorded with version 2.6 cannot be replayed with an older version of REVEN.
- Interrupts could sometimes be replayed at the wrong time in the trace. The fix changes the transition numbers in replayed traces. See compatibility information for more information.
- The taint would sometimes incorrectly taint
raxonxor eax, eaxinstructions. - When using the docker installation method of REVEN, it is now possible to install both the Professional and the Enterprise editions on the same machine.
Analysis Python API
RegisterSlicenow correctly takes the requested slice of the register when the first item is 0 or the last item is the size of the register.TaintView.take_nwould sometimes not return the requested number of results.
Project Manager
- Opening Python from the Project Manager is now more reliable and less impacted by browser blocking pop-ups.
- "Prepare VM" uses a temporary directory for more atomic filesystem operations while extracting the file system.
Axion
- The status bar at the bottom of Axion is no longer displayed when the user disables the corresponding option in the "Windows" menu.
WinDbg integration
- WinDbg's built-in search in memory was not working properly and has been disabled for the time being.
- Improved logging in case of a connection error.
2.5.0
Highlights
REVEN version 2.5 is packed with new features, from GUI and workflow improvements to ever better third party integration! Here are some highlights:
-
Microsoft WinDbg integration: the REVEN server can now act as a Windows machine being debugged by WinDbg. This allows to use the usual debugging commands with REVEN and to get the best of both Windbg debugging and REVEN timeless analysis.
-
Zoomable timeline in Axion: it provides a zoomed view of the main timeline, making it much easier to distinguish between several close search results or bookmarks.
-
New VM installation workflow: a new wizard will guide you through the necessary steps for adding a VM, in particular making it "lighter" for REVEN scenario recording.
-
Improved hexdump management: the hexdump widget is now reused by default when following a memory address, to avoid "hexdump proliferation". The hexdump style has also been reworked for improved clarity.
-
Python API/Axion synchronization: it is now possible to instruct Axion to select a transition from the Analysis Python API.
-
Jupyter Notebook integration: REVEN 2.5 now includes a Jupyter notebook server so that you can easily use the REVEN Analysis Python API on a given scenario from the Project Manager.
-
Server-side bookmarks management: the bookmarks of a scenario are now saved live with the scenario data and exported automatically when exporting a scenario.
Besides, bookmarks are automatically synchronized between Axion clients, making it easy to share key points of interest with other users if you're using REVEN Enterprise.
Improvements
Analysis Python API
- Added
bookmarkmodule that allows to programmatically add, access, edit and remove bookmarks. - Added
address.LinearAddress.translate,address.LogicalAddress.translate,address.LogicalAddressSegmentIndex.translateto translate virtual addresses intoaddress.PhysicalAddress. - Added
trace.Transition.find_inversemethod to get the transition that performs theinverseoperation of the given transition. This feature was previously provided by thepercent.pyscript. - Added
trace.Context.find_register_changemethod to find the next/previous context at which the content of the requested register is modified. - Added
sessionmodule that allows to publish various events to clients like Axion. - Added
RevenServer.sessionsproperty that lists the sessions tracked by theRevenServer. RevenServerandRevenServer.connectnow accept an additional keyword parameter 'sessions'. to set the tracked sessions- In Jupyter Notebook, a
reven2.trace.Transitioninstance now displays as a clickable link that instructs Axion to select that transition in Jupyter Notebook. - Added a
search_in_memory.pyexample script to search patterns in virtual memory. You can find it in theDownloadpage of the Project Manager.
Project Manager
- Starting a REVEN server in the Analyze page of a scenario now generates a Python snippet that can be copied/pasted to scripts and notebooks to connect to the server.
- Added an option to the VM pages to enable UEFI for QEMU VMs.
- Supported QEMU VM format are now detected using QEMU. As a result of this change, the setting variable
QUASAR_QEMU_SCAN_EXTENSIONShas been replaced byQUASAR_QEMU_SCAN_FORMATS.
Axion
- The search combobox now selects the item closest to the currently selected transition when browsing with F4/Shift-F4
- You can now copy the value of a register with a right-click in the CPU widget.
- You can now change the selected instruction by pressing Enter while scrolling a list of memory accesses.
- Double-clicking on a register in the CPU widget will now move the hexdump widget to the value contained in the register.
Fixed issues
Project Manager
- Improved logging when starting up fails due to some external processes.
Axion
- The display of a new widget could sometimes cause the main window to overflow the bottom of the screen. Consequently, the "Maximum docks" option has been removed.
- The trace view now gets the focus upon connecting to a project.
- It was possible to entirely collapse the Hexdump widget and the Strings widget.
- The Trace view would sometimes not follow the cursor when using the percent plugin.
- Clicking on a backtrace item could result in wrong transition numbers being displayed in the CPU widget.
Other changes
- REVEN Enterprise edition now requires a license key to use the software and download software updates. See also upgrading page.
- REVEN is now available as a docker image, allowing to install it on any amd64 Linux.
2.4.0
Highlights
REVEN 2.4 sees the launch of the Professional Edition!
REVEN has been adapted to support Professional licenses accordingly.
Fixed issues
Workflow Python API (preview)
- The Workflow API would sometimes fail a request when a browser was opened on the Project Manager.
Project Manager
- Clearer log messages when starting REVEN fails due to subprocess failures.
Other changes
Automatic scenario recording
- The setting variable
QUASAR_GDB_SERVER_PORT_RANGEis no longer required for the autorecord, so it has been removed.
Axion
- The IDA plugin was renamed to ret-sync plugin because it can be used with both IDA and Ghidra.
2.3.0
Highlights
Ever been frustrated by those missing 32-bit symbols in a REVEN 2.2 trace? Here it is: REVEN 2.3 offers new support for Windows 32-bit OS-Specific Information (OSSI) whether in a 64-bit or a 32-bit scenario.
Ever wanted to easily get the OS process an instruction belongs to? REVEN 2.3 also refines the new APIs brought by REVEN 2.2, adding current process information to the OSSI. Besides, a new status bar in the Trace widget offers detailed contextual OSSI information about the active transition.
OSSI for 32-bit Windows systems
It is now possible to obtain 32-bit symbol information for Windows traces:
- OSSI support for 32-bit DLL in Windows 10 (x64) and Windows 7 (x64) has been added.
- OSSI support for Windows 10 (x86) and Windows 7 (x86) has been added.
Current process information
REVEN 2.3 offers an easy access to the process information associated to a transition in the trace:
- In Axion, in the Trace widget, a new status bar provides detailed OSSI information (process, ring, symbol and binary information) about the active transition. A tooltip with detailed information is provided for each item.
- Process related information is now available through the Analysis API with
Context.ossi.process().
New Guided Tour tutorial of the Axion GUI
REVEN 2.3 comes with a new Guided Tour tutorial of the Axion GUI. Connect to a REVEN scenario with Axion and take the tour!
Axion Menu Overhaul
REVEN 2.3 introduces a brand new menu bar in Axion to make the widgets more readily accessible.
Improvements
Analysis Python API
- Taint API preview: for better compatibility with Axion, marker names created
by
preview.taint.simple_taintare changed from e.g.tag0toTag0.
Workflow Python API (preview)
- Added
ProjectManager.connectto connect to a REVEN project from its name. - Added
ProjectManager.hostnameandProjectManager.portproperties.
Automatic scenario recording
- The autorecord of binary now checks that the required PDBs exist or can be downloaded before launching the recording.
- The recorder logs are now available in the autorecord detail task view,
in the Project Manager
Tasks and Sessionstab. - The autorecord of x86 binaries on x64 Windows now generally results in trace starting at the first instruction of the
binary (on the entry point) rather than the
CreateProcessInternalWfunction. - The overall reliability has been improved.
Project Manager
- Colored dots are now displayed next to the scenario status in the
Scenario Managertab.- Red dots indicate resources that are out-of-date and must be replayed again so that their dependent features work with the current version.
- Orange dots indicate resources that are out-of-date, but compatible with the current version.
- The
kernel_descriptionis now replayed during the 'Replay' step when theOSSIfeature is selected, rather than generated in the 'Prepare' step of the snapshot. This allows to see the current version of thekernel_descriptionresource. - Projects now start faster.
Axion
- When the Symbol Call Search (which is fast) is available, the Symbol Search
(which is slow) is now disabled. In other words, the slower Symbol Search is
only enabled when the
binary_rangesandpc_rangesresources are not available. - The backtrace widget is now faster when the
binary_rangesresource is available.
Fixed issues
Project Manager
- Fixed an issue that prevented having more than one started Axion session in the browser.
Axion
- Search widget: Fixed an issue where selecting an item in the completion list would sometimes result in a different item appearing in the search symbol field.
2.2.1
Highlights
-
T3377 - Fixed a disassembler issue:
- In Axion trace view,
jmpandcallinstructions would sometimes display the wrong target address. - In the Analysis Python API, the
Instructionobject would sometimes contain wrong operands for relativejmpandcallinstructions.
Due to this fix, you may observe longer replay duration for the PC range and stack events resources.
- In Axion trace view,
-
Made it impossible to start non-leaf QEMU snapshots. This fixes an issue where starting such snapshots would corrupt their child snapshots.
Improvements
Analysis Python API
- Improved the performance of the
Context.readmethod up to x3 in typical workloads. - Added a
timeoutargument to theString.memory_accessesmethod, allowing to specify how long this function should attempt to recover all accesses before raising an exception.
Project Manager
-
It is now possible to rename scenarios from the Project Manager web interface. As a result of this change, the name of scenarios must now be unique.
Important: If you already have scenarios that share the same name, they will be renamed upon installation by adding a suffix containing a number to all scenarios sharing the same name. The suffix is
2.2.1-renamed-number. -
The
snapshots > readendpoint of the REST API now adds a list of the live QEMU snapshots in the details of the snapshot. This is useful when doing automatic recording. -
Starting a QEMU snapshot session with more than 2048MB of RAM is now allowed. RAM must not exceed 3072MB on a QEMU snapshot session to record scenarios.
Fixed issues
Analysis Python API
- T3378 - Modified
Stack.backtraceproperty so that it returns a string instead of printing it. - T3388 - Made the
ifregister accessible from the Analysis Python API. Previously, attempting to accessreven2.arch.x64.ifwould raise aSyntaxError, becauseifis a Python keyword. The register is accessible throughreven2.arch.x64.if_.
Project Manager
- Fixed starting Axion and the VM in the browser when a SSH X forwarding connection is open.
Limitations and known issues
Unchanged since 2.2.0.
2.2.0
Highlights
For REVEN 2.2.0, the keyword is Automation, that is, ways to work with REVEN more productively and more in-depth by automating various tasks.
In details, this release is the first version to contain the high-level Analysis Python API, the low-level Workflow Python API, and various facilities for Automatic scenario recording.
Note that this release contains features marked as preview, whose APIs are included for early use. Tetrane is looking forward to your feedback on these new advanced features and accordingly reserves the right to introduce breaking changes to these APIs.
Analysis Python API
It is now possible to use Python to query data from a REVEN server running on a scenario. For this release, supported features include: reading from a Context or a Transition, OSSI, memory history, search, backtrace and strings. The taint feature is also available as a preview package.
Note that the REVEN v2 Python API can be imported from IDA, allowing to combine information from the IDA Python API and the REVEN v2 Python API.
More information on the Python API is available in the quick start guide, that you can find inside the documentation served by the Project Manager.
Workflow Python API (preview)
It is now possible to use Python to automate the workflow of the Project Manager. The API offers methods that allow to perform some of the actions available from the Project Manager web interface.
For more information, please refer to the Project Manager API examples on the Downloads page newly added to the
Project Manager.
Automatic scenario recording (preview)
It is now possible to record QEMU scenarios automatically using the Workflow Python API. Two main workflows are supported today:
- Start recording immediately after starting a binary, and stop recording automatically when the binary exits or crashes. REVEN can also stop the record upon a BSoD.
- Use "magic" ASM instruction sequences to start and stop the record at any time from within the guest VM!
For more information, please refer to the automatic recording cookbook in the documentation served by the Project
Manager and to the various automatic recording examples on the Downloads page of the Project Manager.
Improvements
Project manager
- Added a new
Downloadspage, accessible from the footer, that allows to download various REVEN tools and examples directly from the Project Manager. For instance, the REVEN Python API can be downloaded from this page. - Added a new
API REFERENCElink to the footer that redirects to the Python API reference documentation. - The replay generation time has been improved by about 30% for the PC range, stack events and memory history resources.
- Streamlined port handling in the Project Manager: When the
QUASAR_{PQSL,REDIS,WEBSOCKIFY}_PORTvariables are set to a value, those fixed values are used as port numbers, which makes it easier to put the Project Manager behind a reverse proxy. If set to None or to 0, the corresponding ports are picked randomly among available ports at startup, making it easier to have several Project Manager instances running on the same machine without port conflicts. - Advanced users can now select the number of tasks allowed to run in parallel with the
QUASAR_CELERY_CONCURRENCYvariable. This allows users to fine-tune the behavior of the replay according to the configuration of their machine.
Axion
- Taint widget: the taint is now usable from a remote Axion client! Previously, the taint was only usable if the Axion client was on the same machine as the corresponding REVEN Server. This limitation has now been lifted.
- Taint widget: the widget now displays warnings that occurred during the taint. Warnings tell the users about events that may impact the correctness of the taint. Warnings are displayed in a dedicated "Warnings" tab, and also as a Warning icon next to the affected change in the change view.
- Axion now exposes
reven2rather thanrevenin thePythonQtconsole.
Fixed issues
Project manager
- TIS-34, GS-11, EP-2 - Fixed download PDBs
FileNotFoundErrorthat would stop the task and mark it as failed. - GS-10 - Fixed XSS vulnerability in the Scenario Description field.
- Fixed an issue for scenarios recorded using QEMU, where the last context would sometimes contain incorrect values after replay. Replay your scenario trace and memory history if you need to fix them.
- Fixed an issue where memory usage would increase a lot after running the Project Manager for a long time
- Removed the
Terminallink that was opening a new terminal on the server, but was unreliable.
Axion
- T3103 - Bookmark widget: The "filter" field now filters on all columns of the bookmark rather than just on the transition number
- T3259 - Search widget: Returning many results from a search would result in a freeze of the combo box used to select results upon being clicked. The combo box is now disabled when too many results are returned by a search, and prev/next buttons have been added to iterate the results.
- T3287 - Taint widget: the default shortcut has been changed from Ctrl-T to Alt-T to better accomodate Axion when launched in the browser
- EP-4 - Added a
closebutton to the operand tracer widget that hides the widget
Limitations and known issues
- Only a single taint can run concurrently per REVEN server: currently, starting a second taint, even from a different Axion, will cancel the first running taint. Besides, if two Axion sessions are involved, the first Axion session may display mixed taint results.
- If a taint generates many changes, the taint widget may slow down Axion. Cancelling the current taint operation will revert Axion's slowdown.
- When using the auto-record functionality, the replay operation may fail at the start of the trace with the
following error:
detect_infinite_loops: Assertion 'false' failed. Performing a new scenario recording usually fixes the issue.
2.1.0-beta
Highlights
- Scenario Import/Export: Scenarios can now be exported to share and/or archive them. Refer to the Project Manager documentation for more details.
- Full-web client interface: VMs and Axion can now be used directly in the web browser,
meaning Reverse Engineers can use REVEN from any Linux, Windows or MacOS client and without any client installation.
This feature is currently disabled by default and can be enabled in
settings.py. Please refer to the installation documentation for more details.
Improvements
Project manager (Quasar 2.1.0-beta)
- Light OSSI resource: in order to analyze a scenario with OSSI information, one needs
to prepare the snapshot of the scenario and extract the full filesystem (FS) of the VM. While this operation is still
required, it is now possible to generate a
light FSscenario resource that only contains the files involved in the scenario. This new resource allows to:- Unprepare a snapshot, which will delete the full FS and preserve only the light FS, saving disk space.
- Download PDBs only for the binaries present in the light FS, thus saving bandwidth, time and disk space.
- QEMU snapshot management has been improved:
- Disk and live snaphots can now be deleted from the UI.
- The RAM size is now displayed in MB rather than GB for greater flexibility.
- A new
custom_optionsfield allows user-defined QEMU options to be passed when preparing a VM or recording a scenario. - The RAM size, network options and custom options can be overriden in a snapshot inheriting from a parent snapshot, or before recording a scenario.
- Parameters for the Strings replayer can now be configured in the Project Manager settings.
Axion
- Adding a bookmark now systematically sets the bookmark on the currently selected transition in the Trace view. Previous behavior was widget dependent and possibly confusing.
- A new
--maximizeoption allows to start Axion as a maximized window.
REVEN server
- Taint: Direct Memory Write Accesses (DMA) now correctly untaint memory.
- Taint: the user is warned when the taint encounters FPU instructions, that are not currently supported.
Fixed issues
Project manager (Quasar 2.1.0-beta)
- Tasks: improvements in error handling.
- Fixed some performance issues in page generation.
- PDB downloading: fixed bug where download would fail for file paths containing spaces.
- Various fixes and UI improvements in the VMs, scenario and task/sessions pages.
Axion
- Strings widget: improved stability.
- T2723 - Fixed bookmarking bug where bookmarking a sequence was sometimes impossible.
- T2781 - Trace view: fixed bug where the trace view could be empty.
- T2995 - Fixed percent plugin not working anymore after update.
- T2767 - Fixed Hexdump scroll up "warping" to an unspecified location.
REVEN server
- Taint: fixed some correctness issues.
- Windows OSSI: fixed possible infinite loop while getting the modules of a process.
- T2989, T2406 - Fixed possible REVEN server crash on startup.
2.0.2
Improvements
Axion
- Added load plugin and exec script with file dialog in Axion Python console.
- Use
axion.iexec_script()to execute a script. - Use
axion.iload_plugin()to load a plugin.
- Use
Fixed issues
Axion
- Fixed IDA-sync plugin.
2.0.1
Improvements
Project manager (Quasar 1.0.3)
QUASAR_LIVE_PDB_DOWNLOADis now set toFalseby default.- Improved UI by adding indentation on many pages.
Axion
- T2924 - In widgets displaying tables, the horizontal scrollbar now moves pixel by pixel rather than column by column.
- T2946 - Taint widget: warning emitted by backward taint can now be closed.
- T2904 - Align transition number on the right in the following widgets: memory history, backtrace, bookmark, string access, taint.
- T2917 - Bookmark widget: correctly display binary name when symbol name is unknown.
- T2944 - Demangling: added support of CXX mangle format for Windows64 OS.
- Allowed to use
axion.ext()to exit Axion from plugins.
Low-level bindings
- Bind
get_current_processnetwork service in the low-level bindings.
Fixed issues
Project manager (Quasar 1.0.3)
- Improved UX when errors occur during the start/stop process of the Project Manager.
- Improved error handling when the Project Managers calls external programs that may fail.
- Various fixes and small UI improvements in the scenario and VM management workflow.
Axion
- Backtrace widget: improved performance.
- T2954 - Framebuffer widget: fixed framebuffer not displayed on first transition.
- T2901 - Framebuffer widget: zoomed position in the framebuffer widget is not reset anymore when time-traveling.
- T2898 - Trace view: fixed display of sequences in trace view in some cases.
- Trace view: fixed display of long UTF16 strings.
REVEN server
- T2922 - Taint: Support
iretqandxaddinstructions in the taint. - T2940 - Taint: Improved performance of the backward taint in some use cases.
2.0.0
- Added 64-bit support to REVEN server and Axion to analyze 64-bits Intel systems.
- Released Project Manager (Quasar 1.0.2) to manage all resources needed with REVEN (VMs, snapshots, scenarios, etc.).
REVEN v2 installation guidelines
This section will guide you through the process of installing REVEN for the first time. You will find an overview of REVEN deployment in Annex I.
To upgrade REVEN to a newer version, please read the "Upgrading REVEN" section in the release notes.
License information
REVEN v2 implements programs governed by a free or open source license. The corresponding list of programs, their license(s) and source code are available at https://github.com/tetrane/tetrane-oss. These programs come with ABSOLUTELY NO WARRANTY; before using, modifying or distributing them, please make sure to read their license and accept the attached terms and conditions; you are welcome to redistribute free or open source software under certain conditions.
Pre-requisites
Server hardware
Here are some configuration hints for running an instance of REVEN. When in doubt, don't hesitate to contact us at support@tetrane.com.
NOTE: Installing the REVEN server on a virtual machine is not supported.
Processor
The main CPU bottleneck, when using REVEN with a high performance storage solution, is the replay step, which is using around 4 cores and is highly dependent on single core performance (high frequency and/or high IPC) of the CPU.
In the Professional Edition, you can replay only one scenario at a time. So REVEN will use a maximum of 4 cores for the replay, 2 others for scenario analysis and 2 others cores for the Project Manager.
In the Enterprise Edition, you can replay and analyze an unlimited number of scenarios at a time, so determining how many cores are needed will depend on your usage of REVEN.
Our recommendation is to choose a high-frequency Intel or AMD processor(*) with at least 8 cores. Besides, the most recent processor, the most performance you will get out of it. So, last-gen processors are the best choice. On lower-performance processor, REVEN can still be used but will be slower.
A desktop processor is good enough in a large number of cases. Server processors tend to have a higher number of cores but reduced single core performance. They may be preferred when your workload consists of several concurrent replay tasks or scenario analysis sessions. Mobile processors can be used although they often exhibit lower performance than desktop processors.
(*): Currently, AMD processors can only be used to record QEMU virtual machines, not VirtualBox virtual machines. See the pros and cons of both QEMU and VirtualBox virtual machines here. Unless you have specific recording requirements, we generally recommend using QEMU virtual machines.
Memory
In terms of capacity, in the Professional Edition, the minimum is 16GB but we recommend to have at least 32GB. For the Enterprise Edition, it also depends on your usage (number of simultaneous replays and running REVEN servers).
NOTE: To avoid curbing your high-end processor, having fast enough RAM (frequency + timing) is necessary.
Storage
REVEN is highly I/O performance dependent, and requires at least a SATA SSD, but we recommend having a NVME SSD or better. Note that any type of RAID-0 configuration may help reduce the disk I/O bottleneck. For example if you have a really high-end processor and/or if you will replay multiple scenarios at a time.
As scenarios/VMs can require up to hundreds of GB on disk, the minimum capacity of your storage should be 1TB. We recommend 2TB or more to work on more unarchived scenario in parallel and reduce import/export operations.
We also recommend having extra HDD storage to archive unused scenarios.
Internet access
In the Professional Edition, an active Internet access to https://api.keygen.sh and https://dist.keygen.sh is required while using REVEN.
For both editions, an active Internet access is recommended for downloading symbol information, unless you are using an offline PDB server (see also Obtaining OSSI for a scenario).
Debian operating system
The REVEN v2 package must be installed on a Debian 10 Buster amd64 system.
Storage
The list below shows how REVEN organizes its data, together with the corresponding configuration variables that can be set during the installation process.
-
Installation path:
QUASAR_REVEN_ROOT_PATH
Automatically set bystart.shwith its own directory. -
VM:
QUASAR_QEMU_SCAN_PATH
The VM repository containing the QEMU images, should be fast for snapshot save/load operations. -
REVEN scenarios:
QUASAR_ROOT
VM-specific files such as their filesystems, the REVEN recordings, the replay files, which may be quite large (hundreds of GB). Storage requires a high I/O throughput, to get the best performance out of REVEN (e.g. SSD).
Since this directory will contain SQlite databases, be careful not to have it being in an NFS mount, or you may experience some difficulties and bugs. -
PDBs:
QUASAR_SYMBOL_STORE
Can be shared between users and/or machines. -
Archives:
QUASAR_ARCHIVES_PATH
The scenarios exports. Can be used for backups. Storage can be slow, should be safe (RAID, ZFS, ...). -
Temporary directory:
QUASAR_TMP
A work directory for REVEN. The faster the better. Putting that directory in a RAMFS mount point will even help reduce latency during scenario recording.
Networking
The list below shows networking requirements and options between the REVEN server and other machines. Make sure any filtering device is configured to allow these connections.
-
Main Project Manager interface:
QUASAR_UWSGI_PORT
By default, the Project Manager listens on port 8880. -
VMs and Axion Web usage:
QUASAR_USE_VNC=True
By default, VMs and Axion displays are served through a random port. The settings variableQUASAR_WEBSOCKIFY_PORTallows to set a fixed value for this port. -
VMs and Axion X server usage:
QUASAR_USE_VNC=False
For this usage, you must be able to run X server applications in the terminal where REVEN is started: remote X or native X server will both work.
A common situation is to use SSH X forwarding, in which case the SSH port must be open. -
REVEN server ports for Axion, Python API, WinDbg bridge: REVEN server listens on any port of the ephemeral port range, which defaults to [32768, 60999] on Debian. You may want to access these ports when using Axion, the REVEN Python API or the WinDbg bridge from a remote client. In which cases a VPN may prove useful.
NOTE: Implementing a reverse-proxy in front of REVEN may simplify the requirements on network filtering. Please refer to the specific reverse-proxy section.
-
Connections to the symbol servers:
QUASAR_SYMBOL_SERVERS
Any symbol server listed in the symbol server list must be accessible to the Project Manager and the REVEN server. -
Connection to ret-sync (IDA/Ghidra): IDA/Ghidra synchronization with a REVEN trace requires Axion to connect to the machine running IDA/Ghidra (port 9100 by default). Here again, a VPN may prove useful.
NOTE: When the installation is on a machine using a proxy to access the network you should set QUASAR_HTTP_PROXY and QUASAR_HTTPS_PROXY so that the symbol servers and, in the case of the professional edition, the license server, are accessible. Please refer to the settings file for more information and examples about how to fill out these variables.
Installing REVEN v2
Follow the steps below to install REVEN v2. They must be performed with a regular, non-root user account.
-
Unwrap the REVEN v2 package. You can choose to install it anywhere you want on your file system. Change your current directory to the root of the unwrapped package.
-
Install the required system dependencies:
./install.sh
This will ask for yoursudopassword in order to install the system dependencies.NOTE: For information and documentation about
sudo, please find the Debian documentation here.NOTE: If you have a separate privileged account, then it's not a problem to run
install.shwith this account, since the install process does not depend on any particular user-specific variable. -
Add your user to the group
kvm:
sudo adduser your_user kvm -
Install the REVEN environment:
./start.sh -
Adjust the installation settings:
- Edit the
settings.pyfile to fit your needs.- You'll probably want to touch the
QUASAR_SYMBOL_SERVERSvariable. - By default, the
QUASAR_ROOTwill point in your home directory (~/Reven2). See the storage requirements above for more information.
- You'll probably want to touch the
NOTE: User-wide parameters can also be set in a ~/.config/tetrane/quasar.py
file. It's the recommended place for QUASAR_SYMBOL_SERVERS and custom
QUASAR_ROOT, QUASAR_QEMU_SCAN_PATH, QUASAR_ARCHIVES_PATH,
QUASAR_SYMBOL_STORE, and QUASAR_USE_VNC.
Using REVEN v2 for the first time
REVEN v2 comes with new services accessible through a new web interface named REVEN Project Manager to manage Virtual Machines, scenarios and associated data, and to launch Axion on those scenarios.
Local use from the REVEN host
When locally logged in the REVEN host, use REVEN v2 as follows:
- Launch the Project Manager services, with the following command at the root of the installation directory:
./start.sh
- Then point your favorite web browser to the Project Manager's homepage:
http://your-reven-host:8880/
NOTE: The Project Manager will run X programs for you to record a scenario, or to access the Axion GUI.
Remote use
Through web browser
The simplest way to use REVEN v2 on a remote server, is to set the
QUASAR_USE_VNC setting to True. This will make everything, from the virtual
machines to Axion, to be accessible directly from the browser.
Don't forget to restart the Project Manager after changing this setting.
This feature is known to have a few limitations by design:
- Copy-pasting will work with Axion sessions, but not with VM sessions, since this would require QEMU or VirtualBox to have hooks in the OS they virtualize. This is the same for the "Remote resizing" feature.
- Some keyboard shortcuts may be caught by your desktop environment or web browser before being sent to VNC. This can usually be worked around using the "Extra keys" in the NoVNC UI or reconfiguring your Axion shortcuts.
With X forwarding
When not locally logged in the REVEN host, but working from a remote client, use REVEN v2 as follows:
- Connect to the REVEN v2 host through SSH with X forwarding enabled:
ssh -Y your-login@your-reven-hostThen use the Project Manager as you would locally.
- Launch the Project Manager services, with the following command at the root of the installation directory:
./start.sh
- Point your favorite web browser to the Project Manager's homepage:
https://your-reven-host:8880/
NOTE: In this configuration, other users should not use your REVEN v2 instance as X applications would be redirected to your display.
They will need to launch their own instance of the Project Manager (See next section).
Installing the Axion AppImage package on a remote client
To install Axion (REVEN GUI) on a remote Windows or Linux client, Tetrane provides an AppImage package.
NOTE: Again, connecting an Axion client remotely may require configuring your network. See above for more details.
Installing the Axion AppImage package on Windows 10
- Install Windows Subsystem for Linux (WSL) - follow Microsoft's doc
- Install a linux distribution: the following instructions are valid on Debian & Ubuntu, but the AppImage is designed to work on any other if you prefer a different distribution.
- Install Xming (or another X Windows Server that runs on Windows) and launch it
- Warning: if you run the AppImage in WSL2, you must start Xming through the XLaunch app and check
No Access Controlbecause both your Windows & Linux environments are going to communicate through the network.
- From the WSL shell:
- Install some dependencies from the WSL shell:
# install base dependencies sudo apt update sudo apt install x11-apps sudo apt install libgl1-mesa-glx sudo apt install libharfbuzz-bin # optionally, users can install xfce4 to have a graphical theme sudo apt install xfce4 - Export the display to be able to use graphical applications:
# On WSL1 export DISPLAY=:0 # On WSL2 linux runs on a separate network than the host, so you must point to the host's address # Because of that, you must also create a Windows firewall inbound rule to allow connections to port 6000 # and ensure your X server running on the host allows connection from the WSL guest. export DISPLAY=$(awk '/nameserver / {print $2; exit}' /etc/resolv.conf 2>/dev/null):0 # And to test the display: xeyes - Extract the appimage:
/mnt/c/.../Axion-x.y.z.AppImage --appimage-extract - Execute Axion:
./squashfs-root/AppRun
- Install some dependencies from the WSL shell:
Installing the Axion AppImage package on Linux
All you need to do is make it executable and run it. It is a compressed image with all the dependencies and libraries needed to run the desired software. So there is no extraction, no installation needed. You can uninstall it by deleting it.
Installing a license
Professional edition
After the first launch of the Project Manager, you will be required to install a license.
To install your license you will need to follow the steps below:
-
Point your favorite web browser to the Project Manager's homepage:
http://your-reven-host:8880/. The welcome screen will ask for your license key that was provided to you with your order of the Professional Edition. -
Provide the license key. You will then land on the license activation screen.
-
On the license activation screen, set a name for your current REVEN v2 installation. This operation binds the license to the current server installation. You will then reach the Project Manager home screen.
-
Check the license status in the
Abouttab of the Project Manager. It should display the name of the license holder as specified in your order, the expiry date of your license and the installation name you just provided.
Enterprise edition
NOTE: An active internet connection is not required for installing a REVEN Enterprise license.
After the first launch of the Project Manager, you will be required to install a license.
To install your license you will need to follow the steps below:
-
Point your favorite web browser to the Project Manager's homepage:
http://your-reven-host:8880/. The welcome screen will ask for your license key that was provided to you with your order of the Enterprise Edition. -
Provide the license key.
-
Check the license status in the
Abouttab of the Project Manager. It should display the name of the license holder as specified in your order, if any, and the expiry date of your license.
Stopping REVEN v2
Simply run ./stop.sh at the root of the installation directory, with the same user
that launched start.sh.
Troubleshooting
If you have any trouble somewhere, don't hesitate to take a look at the logs
located in ~/Reven2/<version>/Logs and contact support@tetrane.com for any help.
Moving a REVEN v2 installation directory
If you move the installation directory after running the first start.sh, you'll have
to manually reset the QUASAR_REVEN_ROOT_PATH variable in the settings.py file.
Installing the REVEN v2 Python API
Please refer to the dedicated installation document.
FAQ
What is Quasar?
Quasar is the component implementing the project manager.
The Project Manager is REVEN v2 Web user interface to manage Virtual
Machines, scenarios and associated data, and to launch Axion on those scenarios.
Where do I change the settings?
Per user settings
Some Project Manager settings can be changed at the user level, for
all the versions installed for this user, in the file ~/.config/tetrane/quasar.py.
This file can store settings common to all the user's versions of the Project
Manager, such as the list of symbol servers or some storage paths. It is created
the first time a Project Manager is started for the user.
IMPORTANT: Remember to run stop.sh then start.sh for every running
version of the Project Manager in order to take new settings into account.
Per instance settings
Some Project Manager settings can be changed at the instance level, at
the root of the installation directory, in the file settings.py. It is created
the first time an instance is started.
IMPORTANT: Remember to run stop.sh then start.sh in order to take new
settings into account.
What settings may I change?
Here are some important settings you may want to tune:
QUASAR_ROOT: this is where most of the files will be stored. It is by default in your home directory (~/Reven2), but you may change it to use a custom path.QUASAR_QEMU_SCAN_PATH: this defines where the QEMU Virtual Machine QCOW files will be scanned for registration in the Project Manager. Since this will be scanned recursively, be careful not to put too large a file tree in there, or some Project Manager pages will become very slow.QUASAR_SYMBOL_STORE: this is the symbol cache that REVEN will use for storing PDB files it downloads. If this path is attached to a slow mount point, such as a centralized SSHFS mount point, you may experience latency in the Axion GUI. However, it may be a good idea to share this path with others, since everyone will take advantage of the cache.QUASAR_UWSGI_PORT: port the Project Manager web server will listen to.
What if I want to run multiple instances on the same machine?
You can run multiple instances of Project Manager on the same machine, as long as you set the multiple web interfaces to listen on different ports. You have two solutions to do that:
- Give the port number to
start.shas its first argument:
./start.sh 4000will make the web interface accessible on port 4000. - Set the port number permanently in one of your setting files, with the
variable
QUASAR_UWSGI_PORT, depending on your deployment configuration.
How to use REVEN behind a reverse-proxy?
It's no problem running a REVEN instance behind a reverse-proxy, as long as you follow those recommendations:
- (optional) Change the
QUASAR_UWSGI_PORTto a custom value (e.g. 8888) - Set the
QUASAR_USE_VNCvalue toTrue - Set the
QUASAR_WEBSOCKIFY_PORTto a fixed value (e.g. 6080) - Set the
QUASAR_WEBSOCKIFY_PUBLIC_PORTto the proxied value (e.g. 80) - Set the
QUASAR_JUPYTER_PORTto a fixed value (e.g. 8888) - Set the
QUASAR_JUPYTER_PUBLIC_PORTto the proxied value (e.g. 80)
Here is an example of a working nginx configuration using the above example values:
server {
listen 80;
location / {
proxy_pass http://127.0.0.1:8888/;
proxy_http_version 1.1;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header Host $host;
proxy_set_header Authorization ""; # Ensure we clear the Authorization header for DRF.
}
location /websockify {
proxy_pass http://127.0.0.1:6080/websockify;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $http_connection;
proxy_read_timeout 1800s; # Default is 60s, which is really low in this use-case.
}
location /jupyter/ {
proxy_pass http://127.0.0.1:8888/jupyter/;
proxy_http_version 1.1;
proxy_set_header Host $host;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $http_connection;
}
}
Annex I: deployment overview
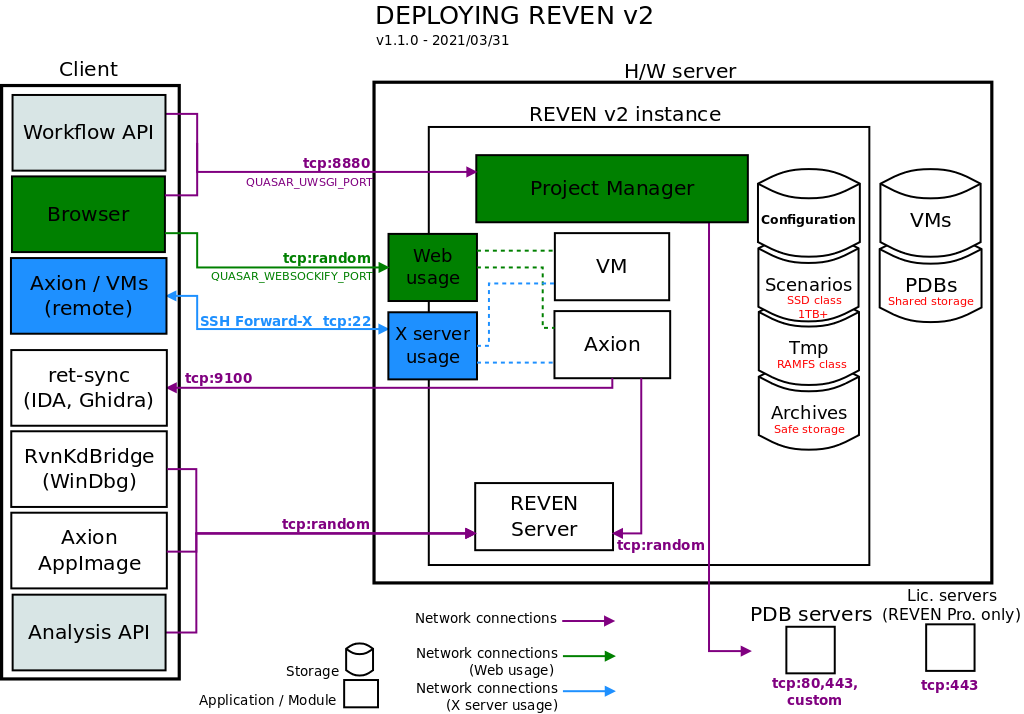
REVEN v2 Project Manager - Quick start
REVEN v2 comes with new services accessible through a Project Manager web interface to manage Virtual Machines, scenarios and associated data, and to launch Axion on those scenarios.
Project Workflow
Once REVEN v2 has been installed, the overall workflow of a Reverse Engineering project goes as follows:
- Create and configure the Virtual Machine (VM) of the project.
- Get OSSI information.
- Configure and record a scenario.
- Replay the scenario and generate analysis data.
- Analyze the scenario with Axion GUI.
Monitoring REVEN v2 tasks and sessions
Using the Project Manager, you can monitor:
- Ongoing tasks such as:
- Replaying a scenario
- Preparing OS-specfic information related to a VM
- Sessions such as:
- Launched REVEN servers
- Launched Axion GUI
Learn more about Tasks & Sessions.
Learn more about exporting and importing scenarios.
Creating and configuring Virtual Machines for your project
With REVEN v2, you can build RE projects where analyzed scenarios are recorded from Virtual Machines(VMs), either VirtualBox or QEMU.
- For most use cases, we recommend using QEMU VMs, to benefit from high-fidelity replays.
- For specific use cases, you can use VirtualBox, such as when:
- VM configuration and setup is a heavy job.
- Some specific hardware must be studied.
- The scenario does not reproduce when emulated in QEMU.
IMPORTANT NOTE: The VirtualBox replayer does not support VMs with more than 2048MB of RAM. Please do not record scenarios with more than this amount of RAM, or the replay will fail.
Records can be started from VM snapshots. The Project Manager allows some control over those snapshots. Here are some keys to understand what's happening.
Introducing VM snapshots
Both QEMU and VirtualBox VMs use two kinds of snapshots:
- Disk snapshots: contain no more than the content of the machine local filesystem. Restoring a disk snapshot brings you to the VM boot, which might not be convenient when recording a scenario.
- Live snapshots: contain the full saved state of a running VM, including the RAM, CPU state, and filesystem. Restoring a live snapshot brings you to the exact VM running state where you took it.
NOTE: In case of modifications in the VM hardware parameters, a live snapshot will probably become unrecoverable.
Please refer to the dedicated VirtualBox and QEMU pages for more information on how to work with each system's snapshots.
Disk snapshot statuses
Disk snapshots can have the following statuses in the Project Manager, relating to OSSI availability:
: Prepared, means the filesystem has been extracted from the snapshot.
: Inherited, means the snapshot "inherits" the OSSI of a parent snapshot. NOTE: If the current snapshot contains new binaries compared to its parent snapshot, OSSI may not be available for these binaries in the Analysis stage. Should you need this OSSI, launch a Prepare operation on the current snapshot.
: Not prepared, means no Prepare operation has occured for this snapshot. Therefore, no OSSI is available for this snapshot. Without OSSI, binary and symbol names will not be available in the Analysis stage.
Windows VM prepartion
On Windows systems, the following preparation steps are required to improve REVEN performance and to make all its features fully operational.
- Disable desktop graphical effects.
- Disable unnecessary services.
- Disable KPTI protections (required to get OS Specific Information (OSSI) such as symbol names).
- Disable the CompactOS option (required for performance and to get OSSI).
Optimizing the VM system for analysis
In order to optimize scenario recording and replay performance, you will need to remove system features that are not useful to your scenarios.
As REVEN will record the entire system execution, the following VM system configuration steps will optimize the virtual machine characteristics and scenario recordings:
- Limit the virtual machine RAM to reduce disk footprint.
- Disable any non essential system features so as to reduce noise in the scenario recording, hence the replay duration, the trace size and complexity, which makes analysis easier and faster.
Disabling unnecessary services
Using the provided Powershell script
Regarding Windows 10 VMs, the REVEN package comes with a sample Powershell script designed to lighten a Windows 10 system, so as to greatly improve its performance and reduce the size of REVEN traces. This script is available from the Downloads page of the Project Manager.
IMPORTANT: Please note that this script is provided to REVEN's users as-is,
without any guarantee, as a convenient tool. Therefore, it must be
considered for what it is - an example. It is strongly recommended to backup
any VM before running the script on it. Besides, the script may require
modifications to fit your specific configurations. For example, non-English VMs
may require some translation in the script, such as administrator to
administrateur in a French VM.
Before using the script, apply the following configuration:
- Disable Windows Defender and optionally the firewall:
- As an Administrator, launch
gpedit.msc. - Navigate to "Local Computer Policy\Computer Configuration\Administrative
Templates\Windows Components\Windows Defender\Turn off Windows Defender" and
set the
Enabledradio button. - Navigate to "Local Computer Policy\Computer Configuration\Windows
Settings\Security Settings\Windows Firewall with Advanced Security" and
set it to
Off.
- As an Administrator, launch
On Windows 10, in an administrator Powershell console, you can:
- Get help about the script's capabilities and usage:
> Get-Help windows10_lightener.ps1
- Run the script to disable a maximum of services:
> Set-ExecutionPolicy Unrestricted
(confirm)
> windows10_lightener.ps1 -All
IMPORTANT: AV disablement by this script is not persistent after a VM reboot, which is is why we recommended disabling it via groups policies above. Alternatively, the script may be executed after each reboot to disable the AV services again:
> Set-ExecutionPolicy Unrestricted
(confirm)
> windows10_lightener.ps1 -DisableAV
Manually disable the following services:
- Print spooler
- DPS
- Themes
- Workstation (SMB protocol)
In order to enable networking, reactivate the following services:
-
Windows Event Log
-
Network Connections
-
Network List Service
-
Run the script to disable basic services only:
> Set-ExecutionPolicy Unrestricted
(confirm)
> windows10_lightener.ps1 -Basic
Using the provided NTLite template
NTLite is a tool easing the process of customizing
Windows. It can be used on either a running system, such as a VM, or on an
installation ISO. The way the provided template is supposed to be used is on a
live, running system.
You will need at least a NtLite Home license to modify your VM.
Please follow the instructions below during the "Lightening of the snapshot" step of the "VM setup" wizard:
- Install NTLite on the VM. You can transfer the NTLite setup file through the "file CDROM" feature.
- Activate your NTLite license on this VM.
- Load the current Windows installation into NTLite.
- Load the provided template by inserting the "Windows 10 lightener CDROM".
- Apply the changes required by the template. A few reboots may be required to fully apply all the modifications.
- You will be done when all the changes will have a green bullet in the "Apply" section of NTLite.
NOTE: Installing NTLite on the VM may require an active internet connection. Please refer to NTLite's documentation for more information about how to install NTLite.
Enable OSSI feature
See the Windows OSSI page on how to enable the feature.
Linux VM preparation
Optimizing the VM system for analysis
On Linux systems, common optimizations include:
- Disabling Xorg server when not needed.
- Disabling the console framebuffer if not needed. For example, on Debian
systems, in file
/etc/default/grub, add the line:
GRUB_TERMINAL=console
- Disabling any unwanted background service.
Enable OSSI feature
See the Linux OSSI page on how to enable the feature.
VirtualBox Virtual Machines
The REVEN server makes use of VirtualBox virtual machines to record the execution of the scenarios you want to analyze. This section describes how to setup a virtual machine that will be suitable for scenario recording.
Pre-requisites
IMPORTANT: VirtualBox is installed during the REVEN server installation process.
IMPORTANT: Should you need some advanced system configuration, such as
dedicating a USB device to a VM, you will have to manually add the Linux
user running REVEN to the Linux group vboxusers. If reven_user is the user
login, this can be done using the command line sudo adduser reven_user vboxusers.
NOTE: Managing remotely a VirtualBox machine may be done through a SSH connection with X-Forwarding enabled or with solutions such as phpVirtualbox or remotebox. We will not document them here.
NOTE: VirtualBox VMs are currently only supported for Intel processors, and not for AMD processors.
Creating VirtualBox VMs for scenario recording
- Create a virtual machine in VirtualBox. Please refer to VirtualBox's online documentation.
- Add an IDE adapter to the VM configuration (or make sure it exists). This can be done through the Storage section of the virtual machine settings:
- Set the IDE adapter name to
reven. - Set it as CD-ROM / primary master device.
- Setup the
Systemsettings as follows: - In the
Processortab, set the number of processors to 1.
- In the
Accelerationtab:- Set the
Paravirtualization interfaceto None. - Check all boxes of
Hardware Virtualization.
- Set the
- Setup the
Audiosettings either disabled, or enabled with the ICH AC97 audio controler selected. Otherwise, the Virtual Machine may not start. - Install the Microsoft Windows or Linux guest OS of your choice on the virtual machine.
WARNING: Make sure to remove any software that may communicate with
the VirtualBox hypervisor from the guest. Intrusive software such as
VirtualBox's Guest additions (which provides extended features like drag
and drop, clipboard sharing and full resolution display) may lead to unhandled
hypervisor behavior, and the recorded scenario will not be properly handled
by REVEN.
VirtualBox snapshots
For a given VM, the Project Manager will show you a single list of VirtualBox snapshots to record scenarios from.
Disk snapshots
This is the equivalent of taking a snapshot while the VM is shut down, or discarding its saved state when taking a snapshot on a running VM.
Live snapshots
This is the saved state you get when you shut the VM down choosing Save state, or when you take a snapshot on a running VM.
Typical VirtualBox usage
We recommend the following approach to prepare a VirtualBox snapshot that will be used for a scenario recording.
In the VirtualBox GUI:
- Create and setup the VirtualBox VM.
- Install software & configuration required by your scenario in the VM.
- Run operations required in the VM before the scenario recording but that need not be recorded.
- Take a snapshot of the VM.
- Shutdown the VM.
In the REVEN Project Manager:
- If the VM has previously been registered, simply refresh the list of snapshots for the VM.
- If the VM has not been registered yet, simply register it. Its snapshots will be automatically known by the Project Manager.
QEMU Virtual Machines
Pre-requisites
IMPORTANT: QEMU is installed during the REVEN server installation process.
The next sections introduce useful QEMU notions to work with REVEN:
- KVM vs Emulated QEMU VMs.
- Disk and live snapshots in QEMU.
KVM vs Emulation
There are two ways to run VMs with QEMU: either using KVM (virtualized mode) or emulated. The former is much faster, but the latter is required when recording. Saved VM states cannot be shared between the two modes, but disk snapshots can.
In the Project Manager's VM view you can select either modes, but when recording a scenario only the emulation mode is available.
KVM mode is convenient when installing software or OSes. See typical workflow below.
For a complete documentation on QEMU tools, please refer to QEMU's online documentation.
How do snapshots work in QEMU
IMPORTANT This section is crucial: REVEN uses the native disk / live snapshot mechanism from QEMU which might differ from what users expect.
There are two types of snapshots available in the qcow file format:
- Disk snapshots represent the state of a disk, and may be organized in a tree structure to save disk space.
- Live snapshots represent the full state of a VM, including memory, cpu registers and disk. They are stored inside a disk snapshot, and are what most users expect.
The two are used in conjunction to provide various functionalities:
- Live snapshots allow the user to store the full state of a VM:
- Loading a live snapshot will allow restoring a VM that is booted.
- These are tightly coupled to the options the VM has been started with: not selecting the right options will prevent snapshots from loading. These options include "kvm", "network", or any custom option.
- They are immutable by design
- Disk snapshots contains the disk only:
- They are mutable: they live with the VM
- Loading a live snapshot will alter the disk snapshot, by restoring it to the saved state. Any modification is lost.
- Starting a VM from a disk snapshot will, by design, require a full boot.
- They can be linked to parent disk snapshots, to limit disk usage on the host. Note that altering a parent snapshot may render children unusable!
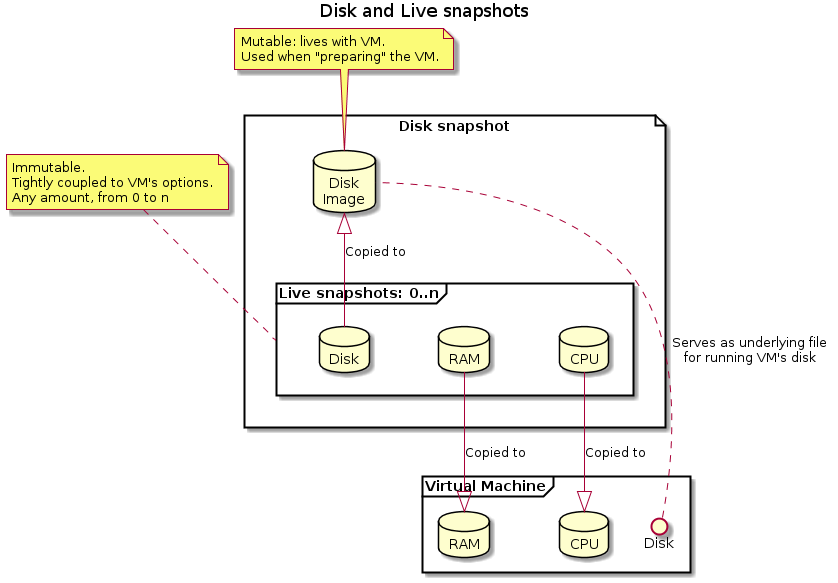
Adding QEMU VMs for scenario recording
Adding an existing VM with the preparation Wizard
REVEN offers a VM preparation Wizard that will guide you in the process of registering and preparing a new QEMU VM in REVEN.
Using this Wizard, you will be able to register:
- VMs that are in supported formats and live in the directory identified
as
QUASAR_QEMU_SCAN_PATHin your settings (by default,~/VMs). The supported formats are listed by theQUASAR_QEMU_SCAN_FORMATSvariable in your settings, see the documentation of this variable insettings.pyfor more information. - Other VMs from your local disk or from a remote URL.
After registering a VM, the Wizard will guide you through the initial steps of snapshot creation and lightening of the VM.
Example 1: adding a Windows 10 VM provided by Microsoft
Microsoft provides some free Windows 10 virtual machines that you can download and use locally, such as the MSEdge VM. Please review the license terms of this VM before using it.
To use this VM with REVEN, please follow the steps below:
- Download the HyperV version from your browser. The HyperV version is preferred because it is known to be compatible, and is lighter than the other versions.
- Unzip the
MSEdge.Win10.HyperV.zipfile you just downloaded. - Use the VM preparation Wizard to upload the
Virtual Hard Disks/MSEdge - Win10.vhdxof the archive from your disk to the server. - Let the VM Wizard guide you through the following steps.
Example 2: adding a VM in OVA format
To use a VM in Open Virtual Appliance (OVA) format with REVEN, please follow the steps below:
- Unzip the OVA archive.
- Use the VM preparation Wizard to upload the
.vmdkor.vdi(depending on the OVA) file contained in the archive from your disk to the server. - Let the VM Wizard guide you through the following steps.
Creating a new QEMU VM from an ISO
You can create a QEMU .qcow2 VM by installing an operating system from an ISO.
The Project Manager does not support all steps required for this operation. As a consequence, in conjunction with using the VM import Wizard, you will also need to run commands via a terminal on the machine REVEN is runnning on. Below are two recommended methods to approach this.
For both methods, you need to know where the Project Manager stores the virtual machine's disks (by default, in ~/VMs) - in the steps below, we will call this path /path/to/VMs/. You can find this out either:
- By starting the registration of a QEMU VM. In the 2nd step, where the wizard asks you to select which disk to import, you can find the VM disk path on the label "Select a VM file from the existing files".
- Alternatively, in your settings file as
QUASAR_QEMU_SCAN_PATH.
You must also copy your installation ISO file on the server by your own means (sFTP, scp, or other). In the next steps, we will call the path to the ISO file /path/to/ISO.
Without direct or SSH access
- In the Project Manager, open the "NOTEBOOKS" link in the page's footer to open Jupyter.
- Once in jupyter, open a new terminal session as follow:
- From the terminal, run
qemu-img create -f qcow2 /path/to/VMs/myimage.qcow2 80G, where/path/to/VMs/is the VM directory found above. Note you should adapt the name and size of the disk to your requirements. - Once this disk is created, you can start importing it using the Project Manager VM import wizard as described in previous sections.
- When asked to create a child snapshot, do so (even if this disk is still empty). Write the name down, we will refer to it as
root. - The first time the wizard requests you start the VM:
- Check "Override custom options",
- Enter the custom option
-cdrom "/path/to/ISO", - Click on "Start" to start the VM with your ISO file.
- If the VM does not show up, use the link "Show in browser". Your ISO file will take precedence in the boot as expected, allowing you to install the VM.
- Once your VM is installed, shut it down properly.
- Leave the Wizard open at this step and go back to the Jupyter terminal.
- At this point, your base disk is empty, and your OS as been installed to the first disk snapshot. Instead we want the base disk to contain this vanilla installation, and later use the first snapshot to lighten the VM further. Hence, "commit" all changes to the base image using the command
qemu-img commit /path/to/VMs/myimage.qcow2.snapshots/root.qcow2. - You can now close the Jupyter terminal. Head back to the wizard. You might get a warning on this page, in which case simply click on the "Refresh" button.
- Uncheck "Override custom options" then click on "Save Setings".
- You are now back into the normal workflow: you can stay at this step to perform the necessary operations to make your VM lighter on
rootby disabling unnecessary services, then continue on to create the first live snapshot and finish the wizard.
With direct or SSH access
If you have direct access to the server and can log into it, or if you can connect to it via SSH, you can run steps similar as above but using your access instead of the Jupyter terminal:
- Get a shell on the server using your SSH or direct access. Make sure you are connected as the user that is running REVEN.
- Continue on with the procedure above, using this shell instead of Jupyter's.
Moreover, if you can run a GUI application on the server (X-forwarding or direct graphical access), you can chose to pre-install the OS to the new disk image prior to importing it in REVEN. Below is a general list of steps you can take in this situation:
- Start your terminal session allowing for GUI application: either by logging into the server's desktop, or by starting an SSH session with X-forwarding (
-Xor-Y). - Execute the command
source /path/to/REVEN/install/sourcemeto make sure you have access to the necessary binaries. - Create your VM disk with
qemu-img create - Manually start the VM, with the iso inserted by running
panda-system-x86_64 -m "2048M" -hda "/path/to/VMs/myimage.qcow2" -usbdevice tablet -enable-kvm -cdrom "/path/to/ISO". Again, adapt parameters as needed. - The VM should show up on your screen and start the installer from the ISO file. Continue on with the installation.
- Shutdown the VM properly.
- You can now run the Project Manager's Wizard to import your newly created VM disk.
Working with QEMU snapshots in REVEN
IMPORTANT NOTE: QEMU replayers do NOT support VMs with strictly more than 3072MB of RAM. DO NOT try to record with more than 3072MB of RAM or the replay will fail. The Project Manager web interface will prevent you from doing that.
In the Project Manager:
- You register a QEMU VM and corresponding disk snapshots are automatically
linked. Besides, both disk and live snapshots can be created.
- Disk snapshots (usually generated with QEMU
qemu-img) can be taken through the Take snapshot button on the VM list page. NOTE: Disks snapshots imply booting the VM, which can be quite long with QEMU without KVM (several minutes for a Windows 10 VM). - Live snapshots (usually generated with QEMU
savevm) can be taken through the Manage button on the VM list page, then in the Running the VM section. You can also access them on the record page of a scenario.
- Disk snapshots (usually generated with QEMU
QEMU snapshots options
By default, when you start a snapshot, it is launched with the VM options (RAM size, network, custom QEMU options) that were provided during the Register VM step. You can override these options for this specific snapshot in the Running the VM section. Overridden options for a snapshot will be applied when starting the VM on this snapshot. You can restore an option to its VM value by unchecking the checkbox associated to this option.
Typical QEMU workflow example
To illustrate the previous explanations, here is how users can typically work with QEMU to configure and prepare a VM before recording a trace:
In the Project Manager VM Manager
- Register an existing QEMU VM.
- Create a disk snapshot for a new project from a clean parent.
- Boot this snapshot with KVM enabled.
- Install required software (using the CD-Rom mounting feature to upload files to the VM).
- Properly shutdown the VM (on Windows, using
Shift+Clickon theShutdownoption is required, otherwise the VM is only hibernated!). - You can now
Preparethe snapshot: all required binaries are present on the disk. - Boot the VM again in emulated mode, i.e. with KVM disabled, with the required options for recording.
- Run operations required before the scenario recording but that need not be recorded.
- Take a live snapshot.
WARNING: live snapshots taken with KVM enabled can not be used for recording in REVEN Project Manager with QEMU.
Then, in the Scenario Manager
- Create a new scenario, selecting the previously created disk snapshot.
- Load the previously created live snapshot.
- Record your trace.
- Force shutdown the VM.
NOTE: At this point, the disk snapshot contains an OS that didn't properly shutdown: it is usually not an issue because restoring the live snapshot will overwrite this state, but booting the VM from the disk snapshot itself will likely trigger any disk verification process the guest OS may have.
NOTE: You can save live snapshot during scenario creation as well, if necessary.
NOTE: For simpler situations, you might have a few live snapshots in emulation mode for various use cases: one with network, one without, etc.
Help! My snapshot doesn't load!
There are a few situations that will prevent a snapshot from loading. In all cases, you can go to the list of Sessions in the Project Manager to get the log of what went wrong. Several checks can be done, depending on the type of snapshot concerned.
Live snapshots
- Make sure the selected options match that of the live snapshot, including kvm mode and custom options. As a convenience, the snapshots's name contains a summary of common ones.
Disk snapshots
- Has the VM been properly shutdown? (
Shift + ClickonShutdownin windows) - Have the parent disk snapshot been modified? If so, children snapshots are unusable
Note that in some cases your disk snapshot may become corrupted leading to the error Image is corrupt; cannot be opened read/write when launching QEMU. It can sometimes occur when having heavy disk I/O or killing QEMU.
To assert the level of corruption of your snapshot you can use the command qemu-img check /path/to/your/snapshot.qcow2.
A possible fix is to ask qemu-img to fix the corruption qemu-img check -r all /path/to/your/snapshot.qcow2.
Working with OS Specific Information (OSSI)
One very important aspect of analyzing a scenario's trace involves mapping the low level transitions in the trace to higher level OS Specific Information (OSSI) such as binary names and symbol names.
As the process is very different from one OS to another, here is the guide for Windows, and here is the one for Linux.
Getting the OSSI for Windows
VM Requirements
- Supported OS: Windows 32 or 64-bit
- CompactOS option: disabled. If the CompactOS option is enabled, the VM
Prepareprocess required to retrieve the binary information will fail. - KPTI protections: disabled. If KPTI protections are enabled, OSSI will be available only on ring 0 or admin processes.
Disabling the KPTI protections
KPTI (Kernel Page-Table Isolation) protections were introduced with the meltdown patches. If KPTI protections are enabled, OSSI will be available only on ring 0 or admin processes.
Microsoft provides the following steps to disable KPTI protections:
reg add "HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\Memory Management" /v FeatureSettingsOverride /t REG_DWORD /d 3 /f
reg add "HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\Memory Management" /v FeatureSettingsOverrideMask /t REG_DWORD /d 3 /f
shutdown -r
Disabling the CompactOS Windows 10 option
On Windows 10, the CompactOS feature lets you run the operating system
from compressed files to maintain a small footprint. However, this feature
is not compatible with the Prepare stage of the REVEN workflow, which is
required by the OSSI features.
Besides, uncompression routines may unnecessarily increase a scenario's trace size.
Therefore it is recommended to check the status of the Compact OS feature on a Windows 10 VM with the following command issued as the Administrator user:
> Compact.exe /CompactOS:query
The system is in the Compact state. It will remain in this state unless
an administrator changes it.
>
If the CompactOS feature is active, it is recommended to disable it:
> Compact.exe /CompactOS:never
Uncompressing OS binaries /
Completed uncompressing OS binaries.
15483 files within 11064 directories were uncompressed.
>
If necessary, it can be later re-enabled:
> Compact.exe /CompactOS:always
Completed Compressing OS binaries.
15483 files within 11064 directories were compressed.
4,454,521,157 total bytes of data are stored in 2,620,926,932 bytes.
The compression ratio is 1.7 to 1.
>
Obtaining OSSI for a scenario
For Microsoft Windows systems, OSSI can be derived from binaries and Program Data Base files, also known as PDBs.
Therefore, obtaining OSSI for a scenario involves:
- Defining remote PDB sources for REVEN.
- Preparing the VM snapshot used for the scenario.
- Downloading PDBs.
Defining PDB sources
Local PDB store
When deriving OSSI, REVEN v2 can look up PDBs from a local PDB store. This
store is defined in the settings.py or quasar.py configuration files:
# The storage for symbol files (PDBs), to pass to REVEN
QUASAR_SYMBOL_STORE = str(Path.home() / Path(".local") / Path("share") / Path("reven") / Path("symbols"))
The store is common to all the scenarios of a REVEN v2 installation.
The default store path is ~/.local/share/reven/symbols.
The PDB store structure respects the following format:
<PDB filename>/<GUID><AGE>/<PDB filename>
example:
E1G6032E.pdb
└── 226C50445B4C4416AF88ED42E0BA63221
└── E1G6032E.pdb
acpi.pdb
└── 3F854976E9FE4734BBB19FD05B5543D11
└── acpi.pdb
d3d10warp.pdb
└── 257F5B0C541C4853B1D1CCC44655DB271
└── d3d10warp.pdb
fltMgr.pdb
└── 620A988036C34BAFAD3FA05B3C5E27FF1
└── fltMgr.pdb
hal.pdb
└── 81C1AF690083498BA941D5EC628CDCF41
└── hal.pdb
i8042prt.pdb
└── 2514B510EC2475DF4224FA4436871A131
└── i8042prt.pdb
ndis.pdb
└── C3E365B8B9DA0007DB598464D3B858CC1
└── ndis.pdb
ntdll.pdb
└── 4E4F50879F8345499DAE85935D2391CE1
└── ntdll.pdb
ntfs.pdb
└── EFB9533DBFF64A4886FB2D975BDBB1101
└── ntfs.pdb
ntkrnlmp.pdb
├── 0DE6DC238E194BB78608D54B1E6FA3791
│ └── ntkrnlmp.pdb
├── 23CA40E78F5F4BF9A6B2929BC6A5597D1
│ └── ntkrnlmp.pdb
├── 2980EE566EE240BAA4CC403AB766D2651
│ └── ntkrnlmp.pdb
└── 83DB42404EFD4AB6AFB6FA864B700CB31
└── ntkrnlmp.pdb
NOTE: Modifying the configuration files requires stopping and starting the Project Manager.
Remote PDB servers
PDBs can be downloaded:
- Explicitly from the Program Manager .
- Transparently while:
- Preparing a VM Snapshot's OSSI.
- Analyzing a scenario in Axion.
PDBs are downloaded from a configured list of PDB servers, based on the binaries present in a VM's Snapshot file system.
The list of PDB servers is defined in the settings.py or quasar.py
configuration files. For example:
# The list of symbol servers to pass to REVEN
QUASAR_SYMBOL_SERVERS = [
"https://msdl.microsoft.com/download/symbols",
]
By default, the list is empty.
Downloaded PDBs are stored the local PDB store.
NOTE: Modifying the configuration files requires stopping and starting the Project Manager.
Preparing a VM snapshot
The Prepare task extract the VM snapshot's file system.
In the Project Manager,
- Browse to the VM manager tab, then to a VM in the list, then to a snapshot.
- Click on the
Preparebutton. - You can monitor and control the
Preparetask in theTasks & Sessionstab.
Learn more about Snapshots statuses
after a Prepare operation.
Downloading PDBs
The downloading of PDBs can be done in 3 ways:
-
Explicitly from the Program Manager:
- Browse to the VM manager tab, then to a VM in the list, then to a snapshot.
- Click on the
Download PDB filesbutton. - You can monitor and control the
PDB downloadtask in theTasks & Sessionstab.
-
Transparently while:
- Preparing a VM Snapshot's OSSI.
- Analyzing a scenario in Axion.
If Enable live PDB download in the scenario's analysis page is checked, each
time a new binary is accessed during the analysis, REVEN will try to download his
PDBs if not in the local PDB store. Be careful, depending on the
network and the size of the PDB, the downloading could last from some seconds to minutes.
Axion will be freezed during this time.
- Manually, you can use the
bin/rabin2tool provided with REVEN v2.
RABIN2_PDBSERVER="<pdb server>" RABIN2_SYMSTORE="<path to the local PDB store>" bin/rabin2 -PP "<binary file>"
Getting the OSSI for Linux
VM Requirements
- PTI and KASLR protections: disabled.
- The kernel headers installed in the VM.
- Compatible kernels: Linux 64-bit, versions 4.1 to 4.14.9 included
- Tested distributions:
- Fedora 27 (kernel version 4.13)
- OpenSUSE 15.1 (kernel version 4.12.14)
- Debian 9 (kernel version 4.9)
- Ubuntu 16.04 (kernel version 4.13)
- Other untested distributions in the compatibility range:
- OpenSUSE 15.0 (kernel version 4.12)
- Ubuntu 17.10 (kernel version 4.13)
- NixOS up to 18.09 (kernel version 4.14)
- ...
Each distribution may have its specific set of patches that can hinder the OSSI retrieval. Feel free to contact support if you cannot get OSSI when using a distribution from the list above.
Disabling KASLR and PTI
You need to add the nopti and nokaslr options to your kernel command line.
On most systems, the following procedure should work almost as-is:
- Edit the file
/etc/default/grub. - Find the variable
GRUB_CMDLINE_LINUX_DEFAULT. - Add the
noptiandnokaslroptions, making the line look like this:GRUB_CMDLINE_LINUX_DEFAULT="[...] nopti nokaslr" - Regenerate your grub configuration:
update-grubfor Debian
grub2-mkconfig -o /etc/grub2.cfgfor CentOS
other distributions should work in a similar way. - Reboot.
- Verify that you have the options present in
/proc/cmdline.
Installing the kernel headers
For Debian-like distributions, this should be done with a command similar to
this one:
sudo apt install linux-headers-$(uname -r)
For RedHat-based distributions, the command is more like the following:
sudo dnf install kernel-devel kernel-headers
Obtaining OSSI for a scenario
This should be as simple as:
- Preparing the snapshot you want to use for the record.
- Recording your scenario.
- Checking the "OSSI" option at the replay step.
However, depending on the distribution you are recording, the generation of the
kernel_description.json resource may fail. In that case, contact the support
to get help in the process of generating it manually.
Maximizing the symbol coverage
By default, symbols are searched within the binaries executed in a scenario. These production binaries usually contain very few symbols.
If debug versions of these binaries, with more symbols, are available on the VM, it is possible to complete the Light Filesystem resource with this information. It can be done manually or using a script.
Creating a new scenario
Once you have VMs and Snapshots all set up, you are ready to create new analysis scenarios.
Creating a scenario involves the following steps:
- Selecting a snapshot to start from, naming and describing the scenario.
- Listing files that must be loaded on CD-ROM before the scenario recording.
- Recording the scenario:
- Starting the VM / Snapshot.
- Starting recording.
- Performing scenario operations in the VM.
- Stopping recording.
- Stopping the VM / Snapshot.
More on scenario recording
Recording a scenario in QEMU
With QEMU, start and stop operations can be triggered via the Web user interface buttons for a manual record, or automatically for a binary record. Please note that automatic binary recording currently only supports Windows 10 x64.
By default, for a record, the VM is launched with the options values of the selected snapshot (ram size, network, custom QEMU options) It is possible to override snapshot options for this specific record before launching the VM. In the Web user interface there are checkboxes and fields that allow to modify the ram size, enable or disable the network or add (QEMU) custom options.
Recording a scenario in VirtualBox
With VirtualBox, start and stop operations are triggered via custom keys, from within the VM:
Inside the VM:
- Type F9 to enable custom keys which are used to start or stop a recording.
- Type F6 or Enter to start recording.
- Type F7 to stop recording. This also stops the VM and closes VirtualBox.
NOTE: Custom keys can be disabled typing F10.
Replaying a scenario
Recording a scenario saves a minimum set of events which are necessary to later reproduce its complete execution trace. The goal here is to minimize the recording overhead.
The Replay stage allows to:
- Retrieve the whole set of events that occured during a scenario.
- Compute new data from this set of events to provide advanced analysis features.
Several sets of data, called resources in the Project Manager, can be replayed from a recording, each corresponding to some analysis feature:
- Trace data
- Memory History data
- Strings data
- Backtrace data
- Binary and symbol indexing data
- Framebuffer data
Learn more about Feature and Resources.
For QEMU scenario only, the replay page allows to add custom options to the replay command (for advanced users only). By default, these options have the same value than the ones used during the record. The ram size is not editable at this step since the replay requires the same amount of ram as the record. When a resource has been generated with custom options, all remaining resources have to be generated with these same options. If you don't want to use custom options anymore, then you should remove the already generated resources that used custom options.
Replaying a scenario will take minutes to hours depending on:
- The REVEN server hardware resources.
- The scenario duration and computing intensity.
- The number of features replayed.
The screenshot below shows the Replay statistics for a QEMU scenario with 2.3 billions transitions on a server equipped with an Intel(r) Xeon(r) CPU E5-2643 v4 @ 3.4GHz and 264GB RAM.
NOTE: The total replay duration is less than the sum of all resource replays since some of them are run in parallel.
Import & export a scenario
Export
When a scenario is recorded, you can export the scenario to share it with other REVEN users or archive it to make space on your disk.
Note that the scenario is not automatically deleted after the export task succeeds (this allows you to export your scenario for others without deleting it). If you want to make space, you need to delete it manually.
Exported scenarios are stored in an archive folder which is
user-definable in the Project Manager settings file via the variable QUASAR_ARCHIVES_PATH (refer to the settings file for the details of available compression types).
A scenario can only be exported once in your archive folder. If you try to export an already exported scenario, it will replace the older archive.
You cannot export a scenario while recording, replaying, importing or exporting it.
The button to export a scenario can be found in the REVEN Project Manager web interface, in the Scenario details page.
Exporting my scenario
You will need to choose what you want to export before launching the export task:
- the record: it is mandatory, you cannot export a scenario without a record included in the archive. Without a record, we cannot replay resources necessary for the analysis.
- the replay: resources generated by a replay are optional. They can be regenerated after the import. We do not recommend keeping them since they add significant overhead to the archive size, which also increases the time necessary to export it.
- the ossi: It is highly recommended to include the OS-specific information. If you don't include them, you won't be able to retrieve OSSI (like symbols) when you will import the archive.
- the light PDBs: Light PDBs contain only PDBs needed for the scenario then they are pretty light. However, even if you do not include them in the archive, you should be able to download them from the location you got them originally.
- the user data: The user data folder is a user folder that contains files useful for the scenario (scripts, readme, ...) you would like to share or retrieve with your imported scenario.
The archive will also always include scenario information (name, type, os, archi, ...) and version information to be sure we can import it.
Importing a scenario
When you have a scenario archive, you can import it in your REVEN Project Manager. It will automatically extract the archive, create the scenario and add it to your scenario list.
An imported scenario cannot be record again. A scenario correspond to a specific record you can edit the description of, replay, analyse and delete.
The scenario will be labelled as Snapshot-less scenario. Since the scenario is imported and an imported scenario already has a record, there is no need for a VM. Therefore the scenario is not and cannot be bound to a VM and a snapshot.
You cannot import a scenario already imported in your REVEN Project Manager.
Some resources are immutable in a Snapshot-less scenario, this means they cannot be regenerated or deleted (if you want to delete them, delete the entire scenario).
Indeed, resources which depend on snapshot information (e.g filesystem) cannot be retrieved since there is not snapshot bound to an imported scenario.
NOTE: OSSI's light filesystem is an immutable resource since the resource depends on the snapshot. This is why you will not have any OS-specific information like symbols or binaries if you do not export them beforehand.
To import a scenario, a button on top of the scenario list in the REVEN Project Manager is available. You will be able to choose an archive from your archive folder.
As soon as you start importing a scenario, you will see it in the scenario list. However, as long as the scenario is in the process of being imported, all actions on the scenario will be disabled.
Tasks & Sessions
Tasks and Sessions are two concepts referring to actions run from the Project Manager. They can be displayed and managed from a dedicated tab in the interface.
Tasks are background jobs such as a replay or a PDB download. Users can launch a task and continue to do their work.
Sessions are directly usable processes such as a started VM, a REVEN server or a running Axion GUI.
Tasks
Tasks aggregate resources replay, VM OS Specific Information (OSSI) preparation and PDBs download.
In the Tasks & Sessions tab, you can perform the following actions on a task:
- Cancel: kills a pending or running task.
- Details: shows a task's characteristics and logs.
- Delete: remove a task's characteristics and logs from the Task list. Be aware that logs can be very useful for bug report and support.
Task statuses
A task can have the following statuses:
: Success, means the task has been completed entirely without any error.
: Failure or Aborted,
means the task has been stopped before the expected end.
This can happen in 2 cases:
- Failed: something went wrong, probably an error occurred during the execution. Please refer to the logs.
- Aborted: task has been canceled on purpose before completion.
: Started, means the task is running.
: Pending, means the task is not started yet. Two reasons can put a task in pending state: waiting for either system resources or replay dependencies to become available.
Sessions
Sessions aggregate interactive processes launched from the Project Manager: REVEN server, Axion and VMs.
In the Tasks & Sessions tab, you can perform the following actions on a session:
- Stop: stops a running session.
- Details: shows a session's characteristics and logs.
- Delete: remove a session's characteristics and logs from the Session list. Be aware that logs can be very useful for bug report and support.
Session statuses
A session can have the following statuses:
: Started, means the session is up and running.
: Stopped,
means the session has been stopped. Either the user closed/killed it manually or
they stopped it from the Tasks & Sessions tab via the Stop button.
Axion - User guide
Axion is REVEN v2 GUI for scenario analysis. It helps reverse-engineer complex programs and situations.
Installing Axion
Axion is comprised in the REVEN v2 package for the Debian 10 Buster x64 servers. Axion is also available as an AppImage package. Please refer to the REVEN v2 installation guide for further guidance on deploying these packages.
Using Axion
Axion can be launched from the Project Manager REVEN v2 web GUI, on scenarios that have appropriate data available for analysis. Please refer to the REVEN v2 Project Manager User Guide for further guidance on preparing a scenario for analysis by Axion.
Axion can also be launched manually on the REVEN server itself or using the AppImage from a remote client.
Core Analysis views
Axion provides several views to analyze a scenario.
- Trace view
- Trace Filter view
- CPU view
- OS Specific Information (OSSI)
- Calltree view
- Backtrace view
- Search view
- Memory - Hexdump view
- Memory - Memory history view
- Memory - Physical history view
- Framebuffer view
- Taint view
Tool views
- Logs
- Bookmarks
Visit the Axion Views page for more details on how to use each view.
Trace navigation
Visit the Trace Navigation page for more details on how to navigate the trace in Axion.
Axion synchronization
You can synchronize Axion with Python clients, for instance to select a transition in Axion from Python.
Visit the Axion synchronization page for more details on this feature.
Plug-ins
OSSI
One very important aspect of analyzing a scenario's trace involves mapping the low level transitions in the trace to higher level OS Specific Information (OSSI) such as binary names and symbol names.
More information about OSSI environment setup can be found here.
In Axion, OSSI is provided in the following views:
Binary information
Binary information is all information related to a segment of memory that is mapped into a process address space. Most of the time, a segment of memory is a binary loaded in memory but it can be a stack, a heap, a part of memory allocated by a process, etc.
A segment of memory is valid for a process and defined by a base address (=start address), a size and a name.
Information is derived from the in-memory OS process map.
If the binary information related to an address is not available, unknown will be displayed. The cause of an unknown information can be that:
- The binary mapping was not found in the
_PEB_LDR_DATAstructure of the running process. - The execution of some code on the heap, on the stack or after a copy in memory.
- The VM used to record the scenario has the
KPTI protectionenabled.
Symbol information
Symbols are part of binary information. A symbol is linked to a memory segment and it is defined by a relative virtual address (RVA) and a name.
A RVA is an offset from the base address of the memory segment. Using a RVA instead of a virtual memory address allows to be independent on where the memory segment is mapped in the process address space.
The sources of symbol information are:
- The binary files.
- The PDB files.
If the symbol related to an address is not available, unknown will be displayed.
Symbol name format
The following example explains what will be displayed in various situations.
Process Address
Space
cr3 = 0x078c0000
| |
| | Example.exe
| | base address = 0x400000
| |
| | rva symbol
0x400000|-------------| .-------------. 0x0 nil
| | | |
| | | |
| | | |
| Example.exe | |-------------| 0x300 Sym1
| | => | |
| | | |
| | |-------------| 0x1200 Sym2
| | | |
| | | |
| | | |
| | | |
0x402000|-------------| '-------------' 0x2000
| |
| |
| |
| |
Possible formats for a symbol's name are:
[0x400000, 0x400300[=>Example.exe_<rva>.0x400300=>Sym1.]0x400300, 0x401200[=>Sym1+0x<offset from rva>.0x401200=>Sym2.]0x401200, 0x402000[=>Sym2+0x<offset from rva>.
NOTE: Currently, in REVEN v2, it is not possible to define custom symbols in a scenario.
Axion Views
Trace view
The Trace view represents the flow of system state transitions in the
recorded scenario under analysis.
Most of the time, a transition is simply an executed instruction. However, sometimes a transition can be:
- A partially executed instruction (normal execution of the instruction was interrupted by a fault).
- An interrupt.
- A fault or an exception.
Transitions are numbered from 0, the first transition in the trace, to T, the last transition in the trace.
The trace is divided into basic blocks. Basic blocks contain transitions
occurring on contiguous code addresses. In the Trace view, each basic block
is identified by the number of its first transition, the name of the
symbol in which the transition occurs and the offset within that symbol.
NOTE: symbol information is only displayed if the OSSI information sources have been previously configured for the scenario's VM and files.
Tips
- You can select any item in the trace, such as an instruction or a register for example. All similar items will be displayed with a yellow background.
- You can select any operand in the trace and, if appropriate, open a
corresponding
Hexdumpview.
Trace Filter view
The Trace Filter view represents a high level view used to filter the trace.
It displays a list of all the processes present in the trace.
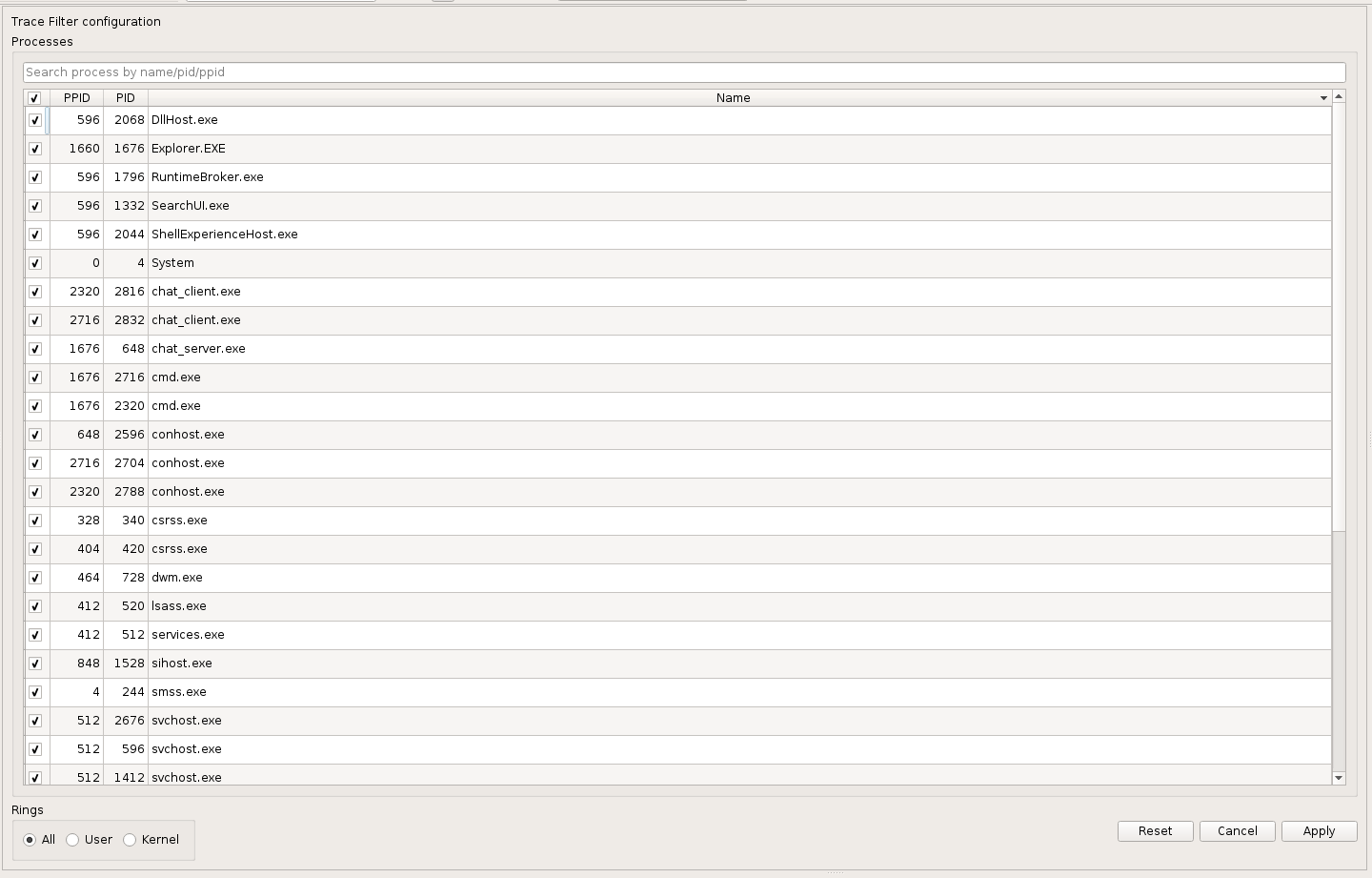
The trace can be filtered by checking/unchecking the processes in the list,
and by selecting which rings are of interest: User space, Kernel space, or both.
In the Trace view, transitions that do not match the filter are displayed with a gray
background.
In the Trace view, navigation from one transition matching the filter to the next one,
skipping the transitions outside the filter, can be done either using the
filter navigation buttons in the toolbar, or the dedicated shortcuts (F6/F7 by default).
It is also possible to move from a range of transitions matching the filter to the previous/next range by using the
filter range navigation buttons in the toolbar, or the dedicated shortcuts (Alt+F6/Alt+F7 by default).
Trace filter toolbar:

A filtered trace view is displayed as the following:
Search view
The Search view allows to search some points of interest in the Trace
view. Points of interests can be:
- Any transition.
- A transition with a given code address executed.
- A transition with a given binary executed.
- A transition with a given symbol executed.
- A transition with a call to a given symbol.
The Search view is composed of:
- A filter form to select points of interest to search.
- A zoomable timeline representing the whole set of transitions in the scenario and displaying where results are found in the trace.
- An exhaustive list of results.

Using the timeline
Going to some place in the trace
The Timeline allows to go directly to some place in the trace just by
clicking on it. A vertical red bar represents the current location in the Trace view.
Manipulating the zoom
The Timeline can be zoomed-in/out using:
- the keyboard with the zoom-in/zoom-out sequence key, usually Ctrl++/Ctrl+-.
- the mouse with Ctrl+WheelUp/Ctrl+WheelDown and Left-click + drag and drop to select the zoom area.
When zoomed in, the background of the zoomed area is white.
The zoomed area can be translated left or right using:
- the keyboard with the Up key, the Left key or the PageUp key (faster) to move to the left and the Down key, the Right key and the PageDown key (faster) to move to the right.
- the mouse with Wheel Up to move to the left and Wheel Down to move to the right.
The zoom can be reset using Ctrl+0.
Searching a sub-range of the trace
On large traces, a sub-range can be selected in the Timeline to reduce the
scope of a search:
- Right-click + drag and drop in the timeline: a green line represents the currently defined sub-range.
Going to a bookmark
The Timeline also displays bookmarks set in the Trace. Click on the
bookmark icon in the timeline to get to the bookmark in the trace.
Searching and browsing some points of interest
- Fill the search form with your search parameters.
- Click the Search button and wait for the results to appear in the timeline and in the result dropbox.
Framebuffer view
The Framebuffer view provides a view of the machine's screen state for a
given transition selected in the Trace view.
NOTE: the Metadata replay must have been run for the Framebuffer view to be available.
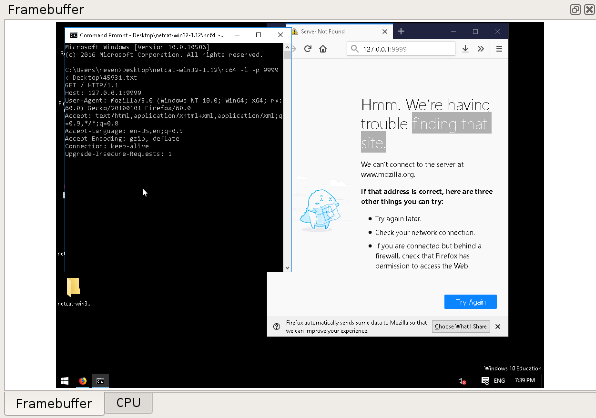
Calltree view
The Calltree view provides a tree representation of the ancestor and sibling calls
around the currently selected transition in the Trace view. This calltree is dependent
on the stack currently in use, and as such is local to the current process and thread.
The following is a code block with its corresponding calltree. The calltree widget adds a
hole item when there are many siblings. This hole item contains buttons that can be used
to request more siblings. In the example below, the hole item represents hidden calls
to function_bottom, made by function_b in a for loop.
|
|
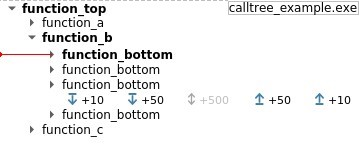
The Calltree view is initialized with a minimal call tree that can be enriched by the user.
List of actions available in the Calltree view:
- Display more sibling

- Display children
- Display more ancestors
The Calltree view displays several other important pieces of information:
- A horizontal red line representing the current selected transition.
- The calls belonging to the current backtrace are displayed with bold font.
- Binary names are displayed at the right side of the view. Only binary changes are displayed. The destination binary of a call is displayed beside the call if its children are hidden.
By default, the Calltree view is updated every time the active transition is changed.
This behavior can be disabled by clicking on the lock button  .
To re-enable it, click on the unlock button
.
To re-enable it, click on the unlock button  .
Only the tree will be locked, the location of the active transition and the current backtrace will still be updated.
Note that if the current transition is not using the stack where the call tree view is locked in,
no current transition will be displayed.
.
Only the tree will be locked, the location of the active transition and the current backtrace will still be updated.
Note that if the current transition is not using the stack where the call tree view is locked in,
no current transition will be displayed.
Double clicking on a call item will change the active transition to the one that make the call. This will not update the tree, even if the widget is unlocked.
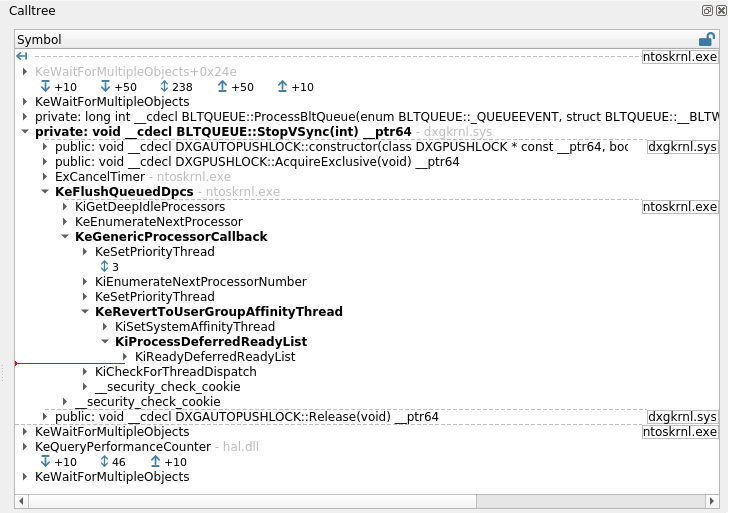
NOTE This view represents an attempt at rebuilding this information from the trace's content, and sometimes cannot be comprehensive. In that case, information from earliest calls may be missing or partial. Therefore double clicking certain entries is not possible.
NOTE: the Stack Events resource must have been replayed for the Calltree view
to be available.
Backtrace view
The Backtrace view provides a list of nested calls for the currently
selected transaction in the Trace view, akin to what would be
expected in a debugger. This backtrace is dependent on the stack currently
in use, and as such is local to the current process and thread.
On the upper part of the widget are two links which, when possible, provide a quick way to navigate between stack switches (i.e. when the stack pointer points to a different stack) - these moments can be process switches, ring changes, process creations, etc. The left link points to the previous stack switch, and the right link to the next stack switch.
Below these links is a list of calls, sorted from latest to earliest. You can double click an entry to get to that call.
NOTE This view represents an attempt at rebuilding this information from the trace's content, and sometimes cannot be comprehensive. In that case, information from earliest calls may be missing or partial. Therefore double clicking certain entries is not possible.
NOTE: the Stack Events resource must have been replayed for the Backtrace view
to be available.
Trampolines
The backtrace as well as the Calltree widgets support trampoline calls. Trampolines are situations where the program calls an intermediary address that in turn jumps to the actual function code. See an example below:
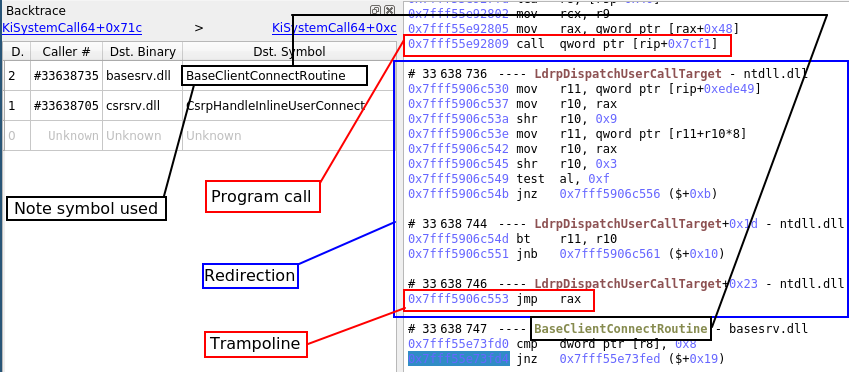
In this case, the selected transition is after both the call the trampoline jmp, so the backtrace displays the target function. However, if the selected transition is between the call and the trampoline jmp, the backtrace will show the call destination:
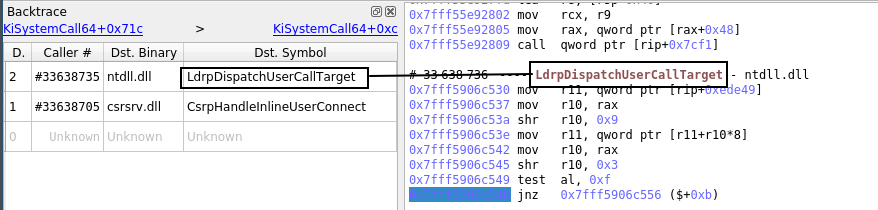
The detection of these trampolines is a heuristic and can sometimes be wrong. It is possible to ignore that information and only show the call destination by unchecking Replace calls with detected trampolines in Axion's Settings dialog window.
CPU view
The CPU view displays the state of CPU registers:
- By default, when a transition is selected in the
Traceview, it shows the CPU registers values before and after the transition. - From the
Timeline, you can also compare the CPU contexts between any two transitions in the trace.
Registers whose value has been modified by a transition or between two transitions are displayed with a yellow background. A checkbox allows you to display only modified registers.
The contextual menu provides the following actions:
- Select memory/register can be used to:
- Browse the register changes with the
Traceview Prev and Next buttons. - Open a new
Hexdumpview at the selected address.
- Browse the register changes with the
- Open an new
Hexdumpview. - Configure which registers must be displayed.
Hexdump view
The Hexdump view shows the content of the memory starting at a given address,
before or after a given transition in the trace.
By default, the Hexdump view that had the focus last will be reused when changing the memory location.
Several Hexdump views can also be opened at the same time for different memory
locations by clicking the "duplicate" button.
If a memory location is not mapped at the selected execution point, ? characters will be displayed instead of its
content.
The "previous/next" arrow buttons of a Hexdump view can be used to go back and forth between visited memory
locations, similar to a browser history.
Memory history
The Memory History view displays the history of the accesses to the selected memory buffer.
NOTE: the Memory History replay must have been run for the Memory History data to be available.
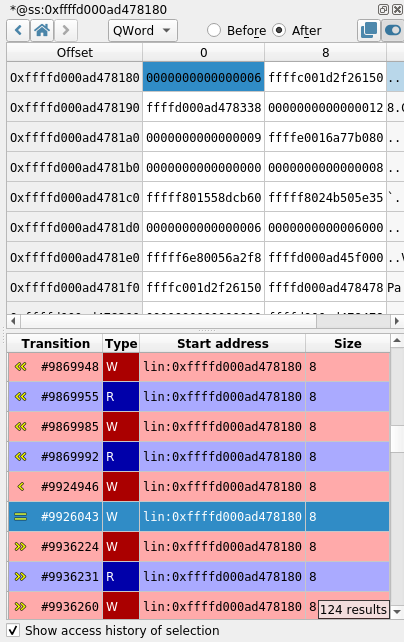
To display the history of a memory buffer:
- In a
Hexdumpview, select a Byte, DWord, QWord or any continuous range of memory. - Check Show access history of selection.
The list of Read and Write accesses to the buffer in the trace will then be displayed, centered on neighboring accesses. Each access is described with:
- A transition number in the trace.
- The access type R for read, W for write.
- The start address of the accessed memory.
- The size of the memory accessed.
To go to the transition in the trace corresponding to a given memory access, double-click its entry in the list.
Note this history reflects the activity of the physical region that the selected virtual area points to. This means that it can contain accesses to this area made through other virtual addresses if for example this area is:
- Shared with another process.
- Mapped elsewhere in the same process.
- Accessed via a physical address directly (by peripherals for instance).
- Reused later on in a different context.
Advanced details
There are a few specific details that are good to know, as they could otherwise be confusing:
- The history may not track internal accesses, such as those performed by the MMU itself while resolving accesses.
- The history does not track failed access attempts leading to page faults - unless if said access spans over more than one page and the first page is mapped but the rest is not, in which case there will be an entry for the first part of this access.
- What would intuitively be expected as a single access may appear sliced into consecutive smaller ones in various cases (access is more than 8 byte large, access spans over more than one page, etc.). This is tracer dependent.
- Certain instructions might generate counter-intuitive accesses: for instance,
BTS(bit test and set) may access a whole 8-byte region. Again, this is tracer dependent.
Strings view
The Strings view allows to display and filter all accessed memory buffers
in the trace that look like valid strings.
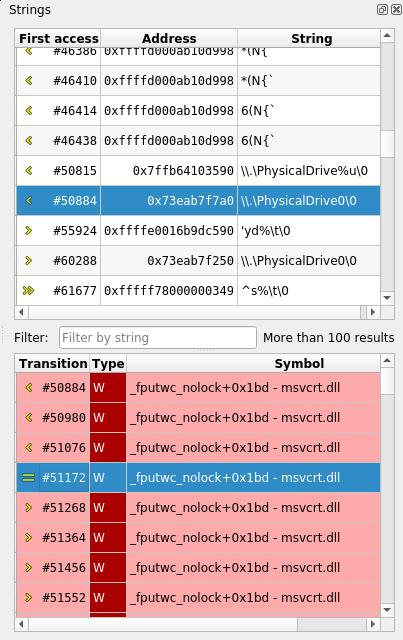
Each accessed buffer is described with:
- A transition number in the trace.
- The memory address of the buffer.
- The string value.
To view the access history of a buffer:
- Select the buffer in the list by clicking on it + Enter or double-clicking on it.
Each entry in the access history shows:
- A transition number in the trace. Double-click on the entry to get
to the transition in the
Traceview. - The access type R for read, W for write.
- The Symbol that performed the access, if known.
NOTE: the Strings replay must have been run for the Strings data to be available.
Taint view
The taint view allows to follow the data flow in the trace, either forward or backward.
The taint analysis automates the task of following some data from memory buffers and registers to other buffers. When performing a backward taint, it allows to find the origin of the tainted data.
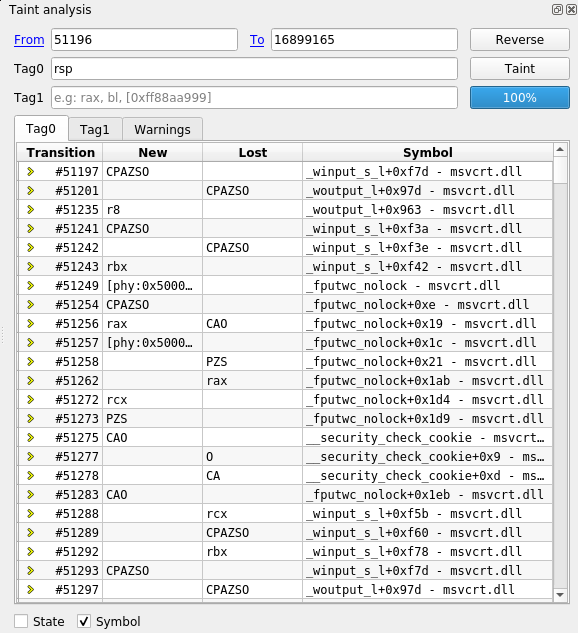
Specifying taint parameters
On the upper part of the widget are some input controls that allow to specify the taint parameters:
Fromindicates the first transition to taint.Toindicates the first transition not in the taint.Tag0andTag1indicate which data should be marked. Different data can be marked inTag0andTag1, in order to follow their propagation in parallel. For more information on what data can be tainted, please refer to the Taint data format section.
To perform a backward taint, the transition number in the To control should
be lower than in the From control (e.g., From = 2968405, To = 0).
Otherwise, the taint will be forward.
The Reverse button allows to swap the content of From and To, switching
between a forward and a backward taint.
Browsing taint results
On the middle part of the widget are several tabs. The Tag0 and Tag1 tabs
each contain a table indicating all changes to tainted data that occurred during
the taint. The Tag0 tab indicates changes that involve data marked with
Tag0, and similarly for Tag1.
For each taint change in the list, the following information is provided:
Transition: the transition number of the change.New: shows data newly tainted.Lost: shows data that just lost taint. You can double click any entry in that list to display the transition where the change occurred in theTraceview.
NOTE: If you encounter any problem with the taint, you can check the
Warnings tab to see some information about what happened during the taint
process. The warnings are also displayed as a clickable Warning icon next to
the affected change in the change view. It is recommended to manually check
changes when there is a warning icon displayed next to them.
The bottom part of the widget can be activated by checking the Display state
checkbox. It presents the current state of all tainted data (regardless of
Tag0 and Tag1) at the transition that is currently selected in the trace.
NOTE: Although, internally, the taint works using physical addresses, the taint attempts to rebuild linear addresses in the taint state view. These linear addresses are clickable links that will open a new hexdump.
Taint data format
Various kinds of data can be tainted, here is a list:
- A register:
rax,rbx,eax,ah - A slice of register:
rax[0:3](is the same aseax),rax[2] - A byte of logical memory (implicit ds segment):
[0x4242]taintsds:0x4242 - A range of logical memory (implicit ds segment):
[0x4242; 2]taintsds:0x4242andds:0x4243 - A byte of logical memory (segment register):
[gs:0x4242]taintsgs:0x4242 - A range of logical memory (segment register):
[gs:0x4242; 2]taintsgs:0x4242andgs:0x4243 - A byte of logical memory (numeric segment index):
[0x23:0x4242]taints0x23:0x4242 - A range of logical memory (numeric segment index):
[0x23:0x4242; 2]taints0x23:0x4242and0x23:0x4243 - A byte of linear memory:
[lin:0x4242]taints linear address0x4242 - A range of linear memory:
[lin:0x4242; 2]taints linear addresses0x4242and0x4243 - A byte of physical memory:
[phy:0x4242]taints0x4242 - A range of physical memory:
[phy:0x4242; 2]taints0x4242and0x4243
NOTE: Several pieces of data can be tainted at once for each tag.
Example: Tag0: [0x2523808; 24], rax[4], rsp, [phy:0x1234f] will tag
ds:0x2523808 through ds:252381f, the fourth byte of rax, the entirety of
rsp and the physical byte at address 0x1234f.
Known limitations
- The taint may fail to propagate the taint on some instructions
(notably,
swapgs). The corresponding warning message isunable to lift instruction. - The taint may fail to propagate correctly on FPU instructions. The
corresponding warning message is
X87 FPU access in forward taint analysis. - The taint uses information obtained at the basic-block level to infer local
simplifications (for instance, it can infer that in the instruction sequence
{mov rax, rbx; xor rax, rbx}, thexoralways resetsraxto 0.). This inference may result in surprising displays in the table views, in backward (some register may lose the taint at one instruction, and some memory may "regain" the taint, apparently from nowhere). This is simply a display limitation and does not otherwise affect the correctness of the taint. - Tainting large ranges of memory (several MB) may result in a very slow taint that uses a lot of CPU.
- Only a single taint can run concurrently per REVEN server: currently, starting a second taint, even from a different Axion, will cancel the first running taint. Besides, if two Axion sessions are involved, the first Axion session may display mixed taint results.
Bookmarks view
The Bookmarks view lists bookmarks that you can create on any transition in
the trace, together with a name and a comment.
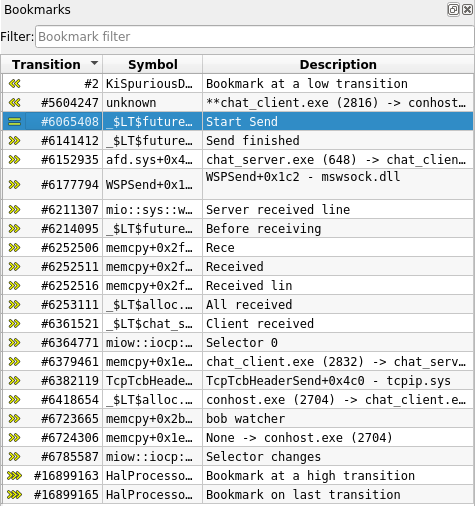
To create a bookmark:
- Select a transition in the
Trace view. - Click right to get to the contextual menu and select Add bookmark (or use the corresponding keyboard shortcut).
Memory watchers view
The Memory watchers view lists watchers that you can create on any virtual memory range in
the trace, together with a name, a basic type information and a description.
In order to be as light as possible during the analysis, the view only displays the watchers' name and their value in memory at the current transition in the trace. To see the description, click right to get the contextual menu and
select Edit.
The value in memory:
- will be updated at each transition change.
- is formatted according to the basic type the memory watcher is assigned.
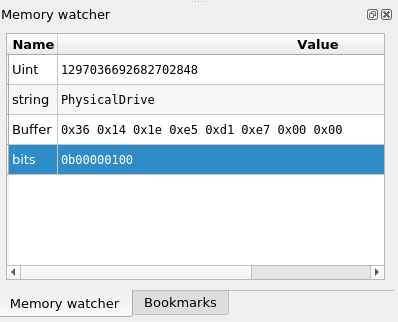
There is 3 ways to create a memory watcher:
-
Manual creation:
- Select the
Viewmenu - Select
Create Memory Watcher
- Select the
-
From a memory operand in the
Traceview:- Double click on an operand
- Click right to get the contextual menu and select
Watch memory
-
From a
Hexdumpview:- Select the memory range to watch.
- Click right to get the contextual menu and select
Watch memory
Logs view
The Logs view displays information, warning, error messages encountered by the Axion GUI.
It is a good idea to check this view when something unexpected occurs in the GUI.
Navigating the trace in Axion
Debugger-like navigation
Axion comes with a set of commands to browse the trace and set the currently selected transition in a debugger-like fashion: step into, step out, step over... forward and backward in the trace.
Overview
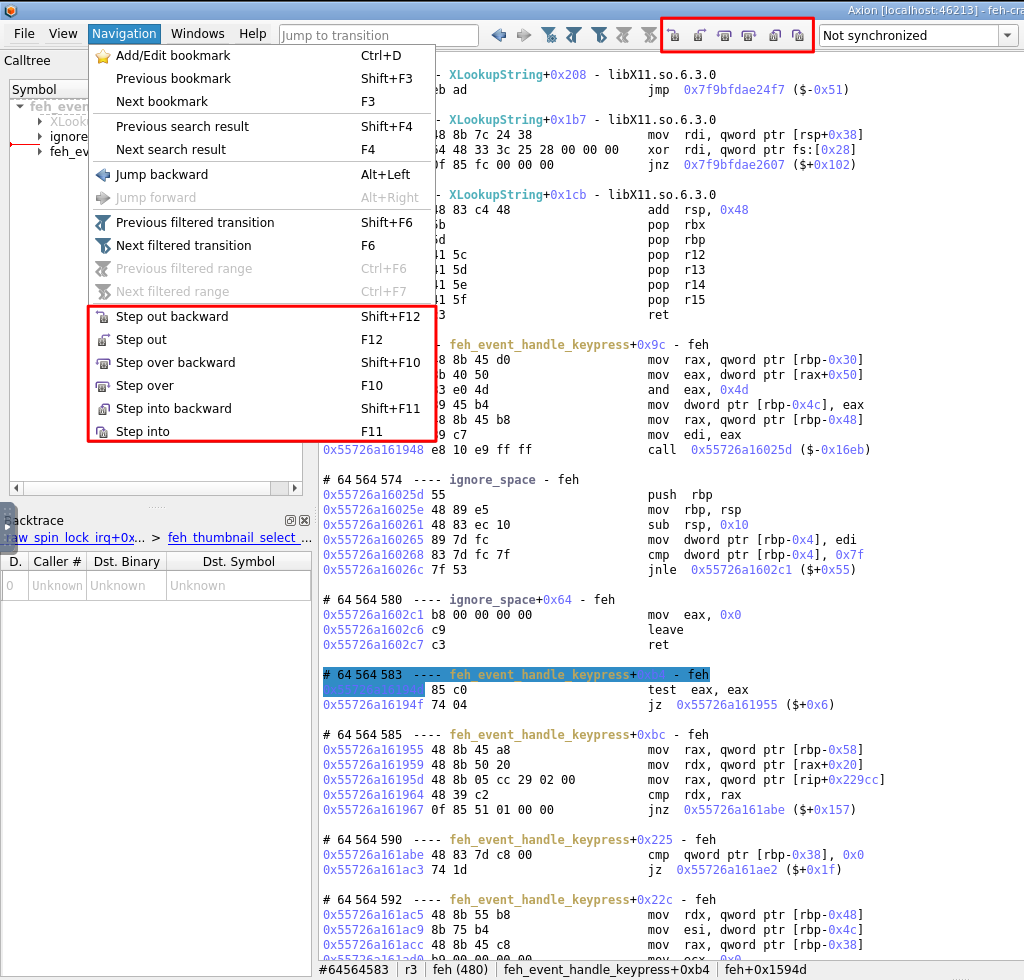
| Action | Default shortcut |
|---|---|
| step over | F10 |
| step over backward | Shift + F10 |
| step into | F11 |
| step into backward | Shift + F11 |
| step out | F12 |
| step out backward | Shift + F12 |
Step out
Use step out to exit the current function:
- step out forward to go to the instruction after the
ret. - step out backward to go the
callinstruction.
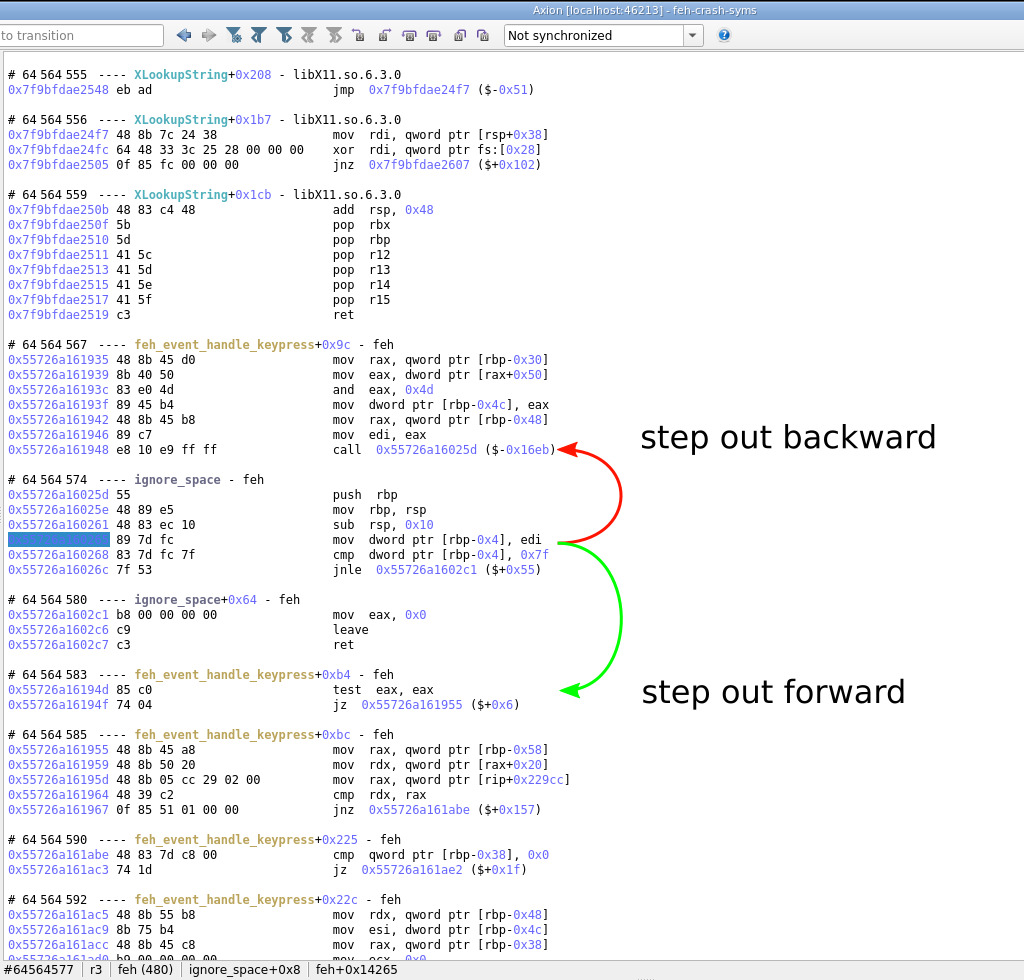
Step into and step over
Forward
On a call instruction, use:
- step into to enter the function (go to the
ret) - step over to skip the function and go to the instruction after the
ret
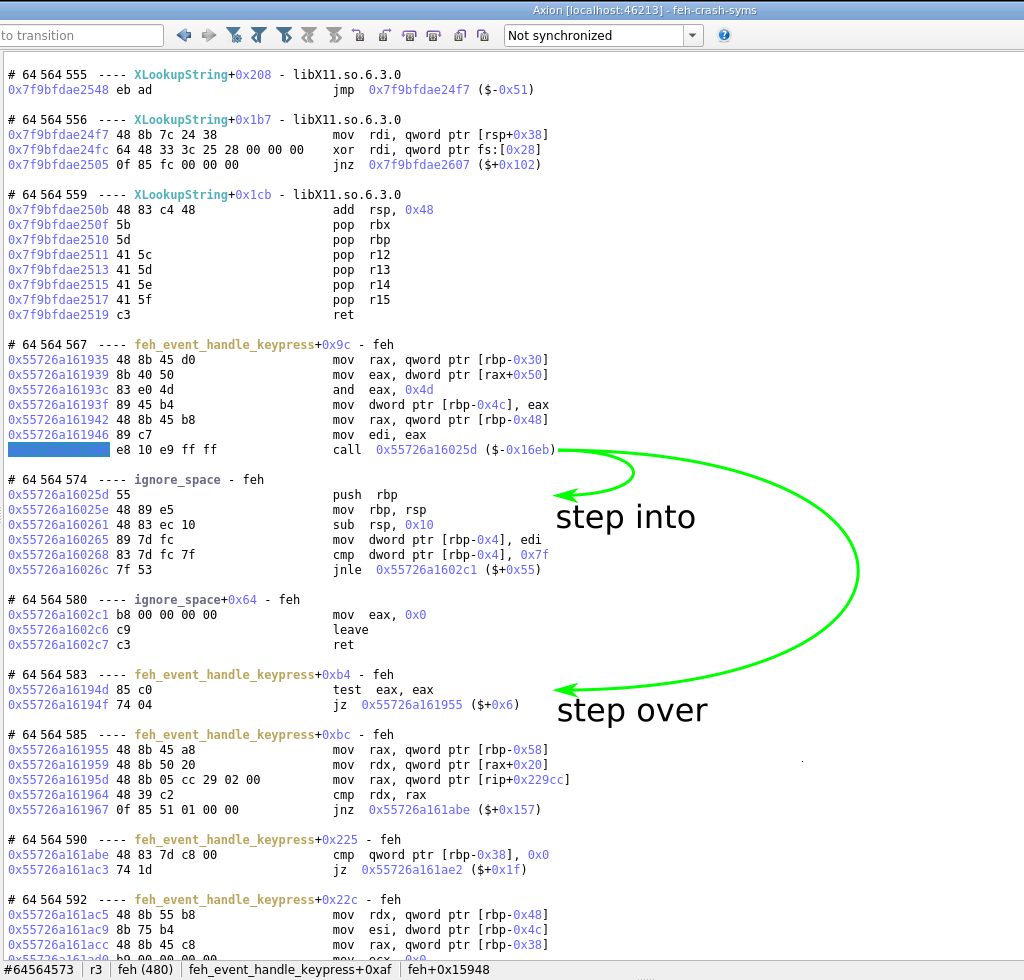
On any other instruction, step into and step over would both go to the next instruction.
Backward
After a ret instruction, use:
- step into backward to enter the function
- step over backward to skip the function and go to the
callinstruction.
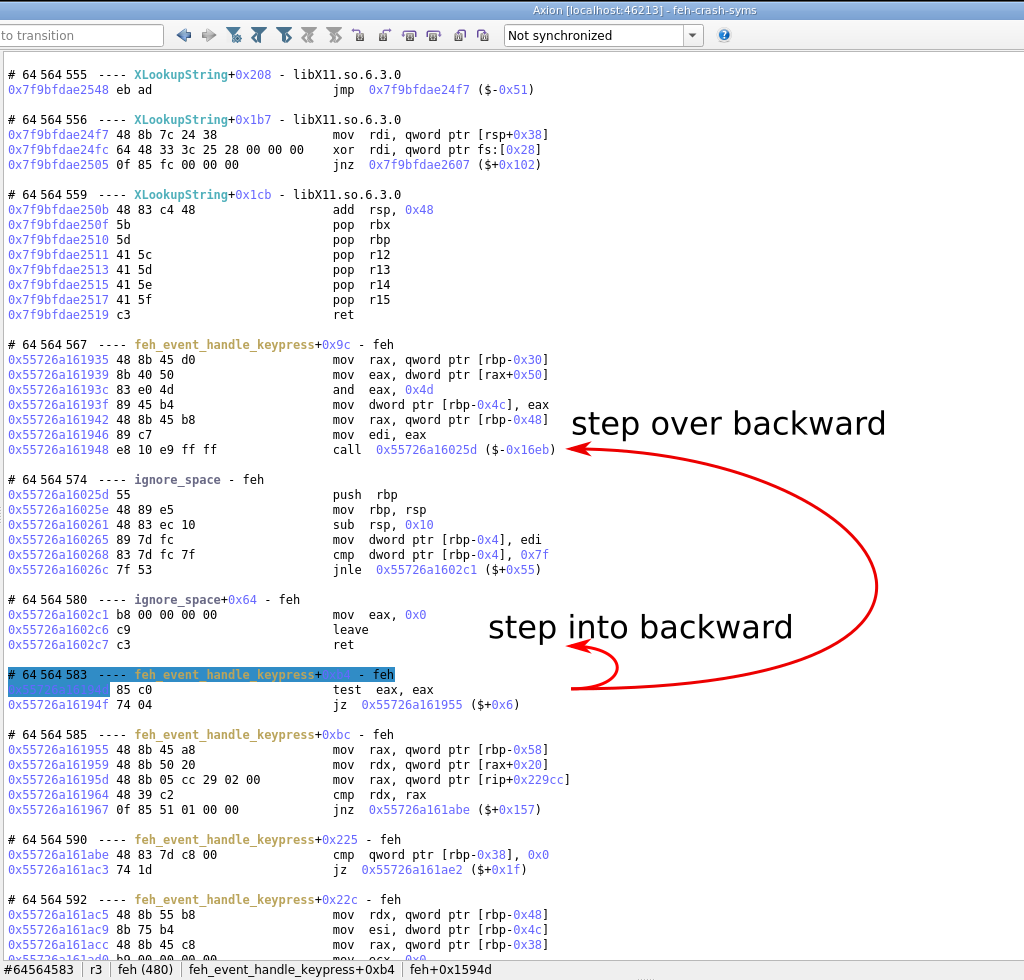
On any other instruction, step into backward and step over backward would both go to the previous instruction.
Reaching the ends of the trace
If the destination of a debugging command was not recorded in the trace (comes from before or after the trace), the step action has no effect and a message is displayed in the status bar and logged in the log widget
Axion percent plugin
The percent plugin adds the capability of jumping between stack memory
accesses. If the currently selected instruction writes something on the stack,
percent will go to the next instruction reading the memory. Conversely, if the
current instruction is reading some value on the stack, percent will jump to
the previous instruction writing the memory. In practice, this is very useful
to follow push/pop operands or call/ret boundaries.
The plugin is named percent as it has been designed to work like the vim editor
percent keybinding on curly brackets.
The default key binding for this plugin is %. If you wish to modify this
binding, use the shortcut configuration panel in Axion
Axion Synchronization
The synchronization feature allows to instruct Axion to select a transition from a Python client connected to the same server.
To do so, you can setup Axion to listen to events sent to a named "session".
Basic setup
The session currently listened to is indicated by the dropdown list on the right of the status menu.

By default, the synchronization is disabled for Axion clients (the "Not synchronized" item is selected).
To enable synchronization, use the session dropdown list to select the Default Session

From there, you can select a transition in Axion from a Python client connected to the same server and the same session:
server.sessions.publish_transition(server.trace.transition(4242)) # Select transition #4242
Please refer to the Python API guide for more information about how to connect to a REVEN server using Python.
Advanced setup
If you want several Axion clients to listen to different Python clients, you can use the session dropdown list and select the "New Session..." item to input a new session name.

This will create a new session on the REVEN server.

From there, you can set up Python to send events to that session, and only Axion clients listening to that session will received them:
# Only the axion client listening to "MySession" will receive events
server.sessions.tracked = "MySession"
server.sessions.publish_transition(server.trace.transition(1212))
Note that we did not need to set the tracked session in the basic setup section, because
the default session is tracked by default.
For more information about sessions handling in the Python API, please refer to the documentation of the Sessions class.
Axion ret-sync Plugin
The Axion ret-sync plugin enables the synchronization of IDA/Ghidra instances with the
currently selected instruction of an Axion instance. It is basically a wrapper
around ret-sync, which is a tool written by Alexandre Gazet.
Setting up the plugin
Prerequisites
In order to use the synchronization working, you must:
- have the OSSI for your scenario activated on the REVEN server.
- ensure network connectivity between the Axion and IDA/Ghidra hosts. In particular, if a firewall is activated, it must allow to open a socket on the selected host and port.
Download the ret-sync tool
To use the plugin, you have to download ret-sync from Github and go to the latest known working git commit.
git clone https://github.com/bootleg/ret-sync
cd ret-sync
git checkout 98698a5705dac4e5ffe834002017a7a339eeb2bc
Configuring the ret-sync tool
ret-sync allows remote setup, that is having IDA/Ghidra on a different host than Axion. To allow this kind of configuration, the ret-sync IDA/Ghidra plugins handles debugger events through a network socket and dispatches them to the right IDA/Ghidra window. More information can be found the Github repository.
The figure below describes how ret-sync is deployed between Axion and IDA/Ghidra.
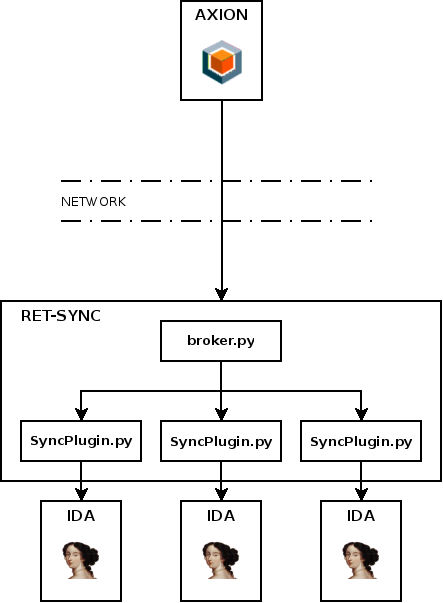
By default, ret-sync will work on a local configuration where IDA/Ghidra and Axion are on the same host (ret-sync will listen on 127.0.0.1). If it is your case you can skip this part.
To allow remote usage of ret-sync, a configuration file must be placed on the
IDA/Ghidra host. The configuration file should be named exactly .sync and can be
located either in the IDB or in the Home directories. The .sync file follows
the .ini syntax and allows setting the host and port the ret-sync will listen
on. eg:
[INTERFACE]
host=192.168.1.16
port=9100
The host option is the IDA/Ghidra host machine address, which can be retrieved by
issuing an ipconfig command on Windows or ifconfig / ip addr on Linux.
Install the ret-sync IDA plugin
IDA7.x
Copy Syncplugin.py and retsync folder from
ret-sync/ext_ida to IDA plugins directory, for example:
C:\Program Files\IDA Pro 7.4\plugins%APPDATA%\Hex-Rays\IDA Pro\plugins~/.idapro/plugins
IDA6.9x
- Go to the
ida6.9xgit tag:
cd <ret-sync dir>
git fetch
git checkout ida6.9x
- Follow the installation step from the README file
Install the ret-sync Ghidra plugin
-
From Ghidra projects manager:
File->Install Extensions..., click on the+sign and select theext_ghidra/dist/ghidra_*_retsync.zipand click OK. This will effectively extract theretsyncfolder from the zip into$GHIDRA_DIR/Extensions/Ghidra/ -
Restart Ghidra as requested
-
After reloading Ghidra, open a module in CodeBrowser. It should tell you a new extension plugin has been detected. Select "yes" to configure it. Then tick "RetSyncPlugin" and click OK. The console should show something like:
[*] retsync init
[>] programOpened: tm.sys
imageBase: 0x1c0000000
The latest known working version of Ghidra for synchronization with Axion is 9.2.2.
Enable the synchronization
Loading target binary in IDA/Ghidra
To synchronize an IDA/Ghidra instance with Axion, you obviously need to load a binary used in the scenario. If you do not already have this binary, you can extract it from the light filesystem of your scenario, in:
SCENARIO_REPLAY_DIRECTORY/light_fs/
If the binary was uploaded to the VM via the CD-Rom, you can also search for it in:
SCENARIO_INPUT_DIRECTORY/
Where SCENARIO_REPLAY_DIRECTORY and SCENARIO_INPUT_DIRECTORY are
respectively the "Replay" and "Input" directories of your scenario, as indicated
in the "Scenario details" page of your scenario in the Project Manager.
Running the ret-sync IDA/Ghidra plugin
IDA7.x
Start the plugin in IDA using the shortcut Alt+Shift+S or via the menu Edit -> Plugins -> ret-sync.
IDA6.9x
Load the file <ret-sync dir>/ext_ida/SyncPlugin.py using the File > Script File menu.
This will create a ret-sync process listening for debugger events.
Once loaded, the plugin will create a new tab in IDA and allow you to change the binary name. IDA-Sync enables the synchronization only when the correct binary is being debugged so you must ensure that the IDA and REVEN binary names are perfectly matching.
Ghidra
Enable the plugin in the Ghidra codebrowser using shortcuts Alt+S.
Running the Axion ret-sync plugin
- Open the Axion ret-sync plugin from the Axion menu
View > ret-sync. - Fill the host and port fields using the machine address and port of the machine where IDA/Ghidra is running on.
NOTE: If the base address of the studied binary is different between Axion and IDA/Ghidra (because of ASLR for example), the synchronisation will still work correctly but the displayed addresses will not match between Axion and IDA/Ghidra. To have the same addresses, the binary in must be rebased to the base address used in Axion. To do that you can use in
- IDA: the menu
Edit > Segments > Rebase Program. - Ghidra: the menu
Window > Memory Mapthen click on the top right house button.
Then you must restart the plugins in IDA/Ghidra and Axion.
REVEN v2 Python API quick start
With the REVEN v2 Python API, reverse engineers can automate the analysis of a scenario using script.
Python API reference documentation
About this document
This document is a quick start guide to the REVEN v2 Python API. The REVEN v2 Python API can be used to automate several aspects of REVEN:
- The recording/replay workflow (Workflow Python API), only available in the Enterprise Edition.
- The analysis of an already replayed scenario (Analysis Python API).
This document focuses solely on the Analysis Python API. It covers the following topics:
- Installation
- Basic usage
- Main concepts
- Overview of the available features
Along the way, this document provides some simple recipes you can use to automate various tasks.
Installation
Please refer to the Installation page for more information on installing the Python API.
You can also use the Jupyter notebook integration to use the API.
Basic usage
Once you've installed the Python API (see the Installation document), you're ready for your first script.
Import the reven2 package:
>>> # Importing the API package
>>> import reven2
Connecting to a server
To use the Python API, you have to connect to a REVEN server started on the scenario you want to analyze. To do this, you must provide the host and port of your REVEN server:
>>> # Connecting to a reven server
>>> hostname = "localhost"
>>> port = 13370
>>> server = reven2.RevenServer(hostname, port)
>>> server
Reven server (localhost:13370) [connected]
If you are using the Python API from the same machine than the REVEN server itself, then the host is "localhost",
otherwise it is the address of your server.
To find the port, you can go to the Analyze page for the scenario you want to connect with, and the port number will be
displayed in the label above the buttons (REVEN running on port xxxx):
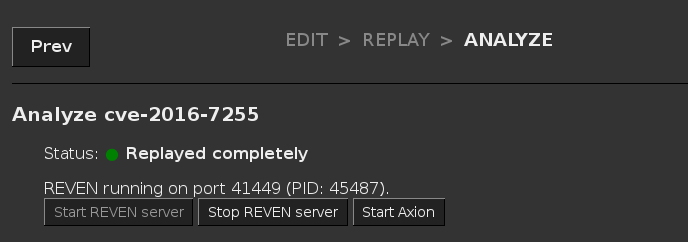
Alternatively, you can find the port in the Active sessions list:
Finally, if you have an Axion client connected to your REVEN server, you can find the port in the titlebar of the Axion window:

Connecting to a server from the scenario's name
NOTE: This section only applies to REVEN enterprise edition.
You can use a feature of the Workflow API to get a connection to a server from the scenario's name, rather than by specifying a port:
>>> from reven2.preview.project_manager import ProjectManager
>>> pm = ProjectManager("http://localhost:8880") # URL to the REVEN Project Manager
>>> connection = pm.connect("cve-2016-7255") # No need to specify "13370"
>>> server = connection.server
>>> server
Reven server (localhost:13370) [connected]
This is useful, as the server port will typically change at each reopening of the scenario, while the scenario name remains the same.
If no server is open for that particular scenario when executing the ProjectManager.connect method call, then a new one will be started.
Root object of the API, tree of objects
The RevenServer instance serves as the root object of the API from where you can access all the features of the API.
The following diagram gives a high-level view of the Python API:
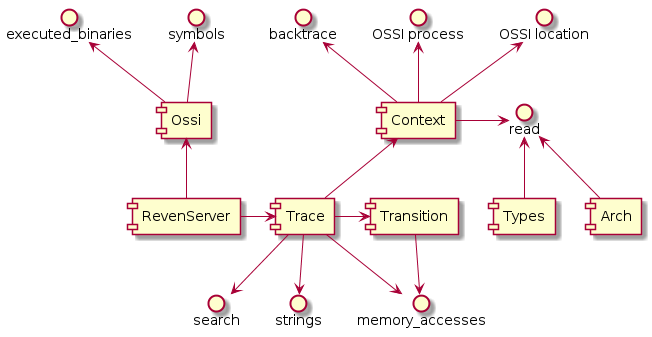
For instance, from there you can get the execution trace and ask for the total number of transitions in the trace:
>>> # Getting the trace object
>>> trace = server.trace
>>> # Getting the number of transitions in the trace
>>> trace.transition_count
2847570054
In your Python interactive shell, you can also use the help built-in function to directly access the documentation while coding (see the official Python documentation for more details on this function).
We recommend using a feature-rich shell like ipython or bpython to benefit from e.g. auto-completion while using the Python API.
Main concepts
Getting a point in time
As is visible in Axion, all instructions are identified by a single unique integer, called the transition id. The transition id starts at 0 for the first instruction in the trace, and is incremented by 1 for each consecutive instruction.
NOTE: We are using the term Transition rather than Instruction here, because technically, not all Transitions in
the trace are Instructions: when an interrupt or a fault occurs, it is also denoted by a Transition that changed the
Context, although no Instruction was executed. Similarly, instructions that execute only partially (due to being
interrupted by e.g. a pagefault) are not considered as normal Instructions. You can see a Transition as a
generalized Instruction, i.e. something that modifies the context.
Getting a transition
You can get interesting transition numbers from Axion's Trace view.
>>> # Getting a transition
>>> transition = trace.transition(1234)
>>> # Displays the transition as seen in Axion
>>> print(transition)
#1234 jne 0xfffff800c9821dc7 ($+0xac)
>>> # Is this transition an instruction?
>>> transition.instruction is not None
True
Getting a context
A Transition is representing a change in the trace, while Contexts represent a state in the trace.
From a transition, you can get either the context before the transition was applied, or the context after the transition was applied:
>>> # Comparing rip before and after executing an instruction
>>> ctx_before = transition.context_before()
>>> ctx_after = transition.context_after()
>>> "0x{:x}".format(ctx_before.read(reven2.arch.x64.rip))
'0xfffff800c9821d1b'
>>> "0x{:x}".format(ctx_after.read(reven2.arch.x64.rip))
'0xfffff800c9821d21'
>>> # Directly getting a context from the trace object
>>> trace.context_before(0x1234) == trace.transition(0x1234).context_before()
True
>>> # Getting a transition back from a context
>>> transition.context_before().transition_after() == transition
True
Reading a context
A common operation on a Context instance is to read the state of the CPU registers as well as memory.
The API provides the read method on Context, that allows to read from a source.
Getting a register or an address
To read from a register source, you can reference elements exposed by the arch package:
>>> import reven2.arch.x64 as regs
>>> ctx = transition.context_before()
>>> ctx.read(regs.rax)
35680
>>> ctx.read(regs.al)
96
>>> # Are we in kernel land?
>>> ctx.read(regs.cs) & 3 == 0
True
To read from a source address, use the address module to construct addresses:
>>> # Comparing the bytes at RIP in memory with the bytes of the instruction
>>> from reven2.address import LogicalAddress, LinearAddress, PhysicalAddress
>>> rip = ctx.read(regs.rip)
>>> instruction = transition.instruction
>>> ctx.read(LogicalAddress(rip, regs.cs), instruction.size) == instruction.raw
True
Reading as a type
The types package of the API provides classes and instance dedicated to the representation of data types.
They allow to read a register or some memory as a specific data type.
>>> from reven2 import types
>>> # Reading rax as various integer types
>>> ctx.read(regs.rax, types.U8)
96
>>> ctx.read(regs.rax, types.U16)
35680
>>> ctx.read(regs.rax, types.I16)
-29856
>>> # Reading in a different endianness (default is little endian)
>>> ctx.read(regs.rax, types.BigEndian(types.U16))
24715
>>> # Reading some memory as a String
>>> ctx.read(LogicalAddress(0xffffe00041cac2ea), types.CString(encoding=types.Encoding.Utf16, max_character_count=1000))
u'Network Store Interface Service'
>>> # Reading the same memory as a small array of bytes
>>> ctx.read(LogicalAddress(0xffffe00041cac2ea), types.Array(types.U8, 4))
[78, 0, 101, 0]
>>> # Dereferencing rsp + 0x20 in two steps
>>> addr = LogicalAddress(0x20) + ctx.read(regs.rsp, types.USize)
>>> ctx.read(addr, types.U64)
10738
>>> # Dereferencing rsp + 0x20 in one step
>>> ctx.deref(regs.rsp, types.Pointer(types.U64, base_address=LogicalAddress(0x20)))
10738
Identifying points of interest
One of the first tasks you need to perform during an analysis is finding an interesting point from where to start the analysis. The API provides some tools designed to identify these points of interests.
Getting and using symbol information
A typical starting point for an analysis is to search points where a specific symbol is executed. In the API, this is done in two steps:
- Identify the symbol in the available symbols of the trace.
- Search for the identified symbol.
For the first step, you need to recover the OS Semantics Information (OSSI) instance tied to your RevenServer instance:
>>> # Recovering the OSSI object
>>> ossi = server.ossi
Note that for the OSSI feature to work in the API, the necessary OSSI resources must have been generated. Failure to do so may result in several of the called methods to fail with an exception. Please refer to the documentation of each method for more information.
From there you can use the methods of the Ossi instance to get the binaries that were executed in the trace, and all
the symbols of these binaries.
Note that each of these methods, like all methods returning several results of the API, return Python generator objects.
>>> # Getting the first binary named "ntoskrnl.exe" in the list of executed binaries in the trace
>>> ntoskrnl = next(ossi.executed_binaries("ntoskrnl.exe"))
>>> ntoskrnl
Binary(path='c:/windows/system32/ntoskrnl.exe')
>>> # Getting the list of the symbols in "ntoskrnl.exe" containing "NtCreateFile"
>>> nt_create_files = list(ntoskrnl.symbols("NtCreateFile"))
>>> nt_create_files
[Symbol(binary='ntoskrnl', name='NtCreateFile', rva=0x4123b0), Symbol(binary='ntoskrnl', name='VerifierNtCreateFile', rva=0x6cf7bc)]
Once you have a symbol or a binary, you can use the search feature to look for contexts whose rip location
matches the symbol or binary.
>>> # Getting the first context inside of the first call to `NtCreateFile` in the trace
>>> create_file_ctx = next(trace.search.symbol(nt_create_files[0]))
>>> create_file_ctx
Context(id=14771105)
>>> # Getting the first context executing the `whoami.exe` binary
>>> whoami = next(ossi.executed_binaries("whoami.exe"))
>>> whoami_ctx = next(trace.search.binary(whoami))
>>> whoami_ctx
Context(id=2616590520)
For any context, you can request the current OSSI location and process:
>>> # Checking that the current symbol is NtCreateFile
>>> create_file_ctx.ossi.location()
Location(binary='ntoskrnl', symbol='NtCreateFile', address=0xfffff800c9c133b0, base_address=0xfffff800c9801000, rva=0x4123b0)
>>> # Getting the current process
>>> create_file_ctx.ossi.process()
Process(name='ShellExperienceHost.exe', pid=2412, ppid=616, asid=0x6a09e000)
>>> # When the symbol is unknown it is not displayed and set to None
>>> trace.context_before(1639373926).ossi.location()
Location(binary='sppsvc', address=0x7ff62952c880, base_address=0x7ff629390000, rva=0x19c880)
>>> trace.context_before(1639373926).ossi.location().symbol is None
True
>>> # When the whole location is unknown it is set to None
>>> trace.context_before(2215773766).ossi.location() is None
True
You can also request the location corresponding to a different (currently mapped) cs virtual address:
>>> # Requesting the 'NtCreateFile' symbol location from a context at a different location
>>> ctx.ossi.location()
Location(binary='ntoskrnl', symbol='PoExecutePerfCheck', address=0xfffff800c9821d1b, base_address=0xfffff800c9801000, rva=0x20d1b)
>>> ctx.ossi.location(0xfffff800c9c133b0)
Location(binary='ntoskrnl', symbol='NtCreateFile', address=0xfffff800c9c133b0, base_address=0xfffff800c9801000, rva=0x4123b0)
>>> # Moving a bit changes the rva
>>> hex(ctx.ossi.location(0xfffff800c9c133df).rva)
'0x4123df'
Searching executed addresses in the trace
If you don't have a symbol attached to your address, you can also search for a specific address using the search function:
>>> # Searching for an executed address we saw in `whoami.exe`
>>> whoami_ctx == next(trace.search.pc(0x7ff72169c730))
True
Searching for strings in the trace
You can use the strings feature to search points in the trace where strings are first accessed or created:
>>> # Looking for a string containing "Network"
>>> string = next(trace.strings("Network"))
>>> string
String(data='Network Store Interface Service\\0', size=64, address=LinearAddress(offset=0xffffe00041cac2ea), first_access=#40814 movdqu xmm0, xmmword ptr [rdx + rcx], last_access=Transition(id=40828), encoding=<Encoding.Utf16: 1>)
>>> # Getting the list of memory accesses for the string
>>> for access in string.memory_accesses():
... print(access)
...
[#40814 movdqu xmm0, xmmword ptr [rdx + rcx]]Read access at @phy:0x7cffb2e8 (virtual address: lin:0xffffe00041cac2e8) of size 8
[#40815 movdqu xmm1, xmmword ptr [rdx + rcx + 0x10]]Read access at @phy:0x7cffb2f0 (virtual address: lin:0xffffe00041cac2f0) of size 16
[#40821 movdqu xmm0, xmmword ptr [rdx + rcx]]Read access at @phy:0x7cffb300 (virtual address: lin:0xffffe00041cac300) of size 16
[#40822 movdqu xmm1, xmmword ptr [rdx + rcx + 0x10]]Read access at @phy:0x7cffb310 (virtual address: lin:0xffffe00041cac310) of size 16
[#40828 movdqu xmm0, xmmword ptr [rdx + rcx]]Read access at @phy:0x7cffb320 (virtual address: lin:0xffffe00041cac320) of size 16
Manually iterating in the trace
Another way of searching interesting points is by iterating over contexts or transitions, and then looking for various information by inspecting the context or transition. Beware that if you iterate on a large portion of the trace, it may take a very long time to complete, so prefer the predefined search APIs that use optimized indexes whenever it is possible.
>>> # Finding first instruction whose mnemonic is swapgs
>>> # Warning: this example may take some time to execute
>>> def find_mnemonic(trace, mnemonic, from_transition=None, to_transition=None):
... for i in builtins.range(from_transition.id if from_transition is not None else 0,
... to_transition.id if to_transition is not None else trace.transition_count):
... t = trace.transition(i)
... if t.instruction is not None and mnemonic in t.instruction.mnemonic:
... yield t
...
>>> next(find_mnemonic(trace, "swapgs"))
Transition(id=184230)
Combining the predefined search APIs with manual iteration allows to iterate over a smaller portion of the trace to extract useful information:
>>> # Finding all files that are created in a call to NtCreateFile
>>> def read_filename(ctx):
... # filename is stored in a UNICODE_STRING structure,
... # which is stored inside of an object_attribute structure,
... # a pointer to which is stored as third argument (r8) to the call
... object_attribute_addr = ctx.read(regs.r8, types.USize)
... # the pointer to the unicode string is stored as third member at offset 0x10 of object_attribute
... punicode_addr = object_attribute_addr + 0x10
... unicode_addr = ctx.read(LogicalAddress(punicode_addr), types.USize)
... # the length is stored as first member of UNICODE_STRING, at offset 0x0
... unicode_length = ctx.read(LogicalAddress(unicode_addr) + 0, types.U16)
... # the buffer is stored as third member of UNICODE_STRING, at offset 0x8
... buffer_addr = ctx.read(LogicalAddress(unicode_addr) + 8, types.USize)
... filename = ctx.read(LogicalAddress(buffer_addr),
... types.CString(encoding=types.Encoding.Utf16, max_size=unicode_length))
... return filename
...
>>> for (index, ctx) in enumerate(trace.search.symbol(nt_create_files[0])):
... if index > 5:
... break
... print("{}: {}".format(ctx, read_filename(ctx)))
...
Context before #14771105: \??\C:\Windows\SystemApps\ShellExperienceHost_cw5n1h2txyewy\resources.pri
Context before #14816618: \??\PhysicalDrive0
Context before #16353064: \??\C:\Users\reven\AppData\Local\...\AC\Microsoft
Context before #16446049: \??\C:\Users\reven\AppData\Local\...\AC\Microsoft\Windows
Context before #16698900: \??\C:\Windows\rescache\_merged\2428212390\2218571205.pri
Context before #26715236: \??\C:\Windows\system32\dps.dll
Moving in the trace
Once you identified point(s) of interest, the next step in the analysis is to navigate by following data from these points.
The API provides several features that can be used to do so.
Using the memory history
The main way to use the memory history in the trace is to use the Trace.memory_accesses method.
This method allows to look for the next access to some memory range, starting from a transition and in a given
direction:
>>> # Choosing a memory range to track
>>> address = LogicalAddress(0xffffe00041cac2ea)
>>> # Getting the next access to that memory range from the current point
>>> memhist_transition = trace.transition(40818)
>>> next(trace.memory_accesses(address, size=64, from_transition=memhist_transition))
MemoryAccess(transition=Transition(id=40821), physical_address=PhysicalAddress(offset=0x7cffb300), size=8, operation=MemoryAccessOperation.Read, virtual_address=LinearAddress(offset=0xffffe00041cac300))
>>> # Getting the previous access to that memory range from the current point
>>> next(trace.memory_accesses(address, size=64, from_transition=memhist_transition, is_forward=False))
MemoryAccess(transition=Transition(id=40815), physical_address=PhysicalAddress(offset=0x7cffb2f8), size=8, operation=MemoryAccessOperation.Read, virtual_address=LinearAddress(offset=0xffffe00041cac2f8))
>>> # Getting all accesses to that memory range in the trace
>>> for access in trace.memory_accesses(address, size=64):
... print(access)
...
[#40814 movdqu xmm0, xmmword ptr [rdx + rcx]]Read access at @phy:0x7cffb2e8 (virtual address: lin:0xffffe00041cac2e8) of size 8
[#40815 movdqu xmm1, xmmword ptr [rdx + rcx + 0x10]]Read access at @phy:0x7cffb2f0 (virtual address: lin:0xffffe00041cac2f0) of size 8
[#40815 movdqu xmm1, xmmword ptr [rdx + rcx + 0x10]]Read access at @phy:0x7cffb2f8 (virtual address: lin:0xffffe00041cac2f8) of size 8
[#40821 movdqu xmm0, xmmword ptr [rdx + rcx]]Read access at @phy:0x7cffb300 (virtual address: lin:0xffffe00041cac300) of size 8
[#40821 movdqu xmm0, xmmword ptr [rdx + rcx]]Read access at @phy:0x7cffb308 (virtual address: lin:0xffffe00041cac308) of size 8
[#40822 movdqu xmm1, xmmword ptr [rdx + rcx + 0x10]]Read access at @phy:0x7cffb310 (virtual address: lin:0xffffe00041cac310) of size 8
[#40822 movdqu xmm1, xmmword ptr [rdx + rcx + 0x10]]Read access at @phy:0x7cffb318 (virtual address: lin:0xffffe00041cac318) of size 8
[#40828 movdqu xmm0, xmmword ptr [rdx + rcx]]Read access at @phy:0x7cffb320 (virtual address: lin:0xffffe00041cac320) of size 8
[#40828 movdqu xmm0, xmmword ptr [rdx + rcx]]Read access at @phy:0x7cffb328 (virtual address: lin:0xffffe00041cac328) of size 8
Note that the memory history works with physical addresses under the hood. Although it accepts virtual addresses in input, the range of virtual addresses in translated to physical ranges before querying the memory history. As a result, the vitual address range needs to mapped at the context of the translation for the call to succeed.
A secondary method to use is the Transition.memory_accesses method that provides all the memory accesses that occurred
at a given transition.
>>> # Getting all memory that is accessed during a "rep mov" operation
>>> rep_tr = trace.transition(49579) # found with "find_mnemonic"
>>> print(rep_tr)
#49579 rep outsd dx, dword ptr [rsi]
>>> [(access.virtual_address, access.size) for access in rep_tr.memory_accesses()]
[(LinearAddress(offset=0xffffe000427c6fb0), 2), (LinearAddress(offset=0xffffe000427c6fb2), 2), (LinearAddress(offset=0xffffe000427c6fb4), 2), (LinearAddress(offset=0xffffe000427c6fb6), 2), (LinearAddress(offset=0xffffe000427c6fb8), 2), (LinearAddress(offset=0xffffe000427c6fba), 2)]
Using debugger commands
From any transition, you can move to the beginning/end of the current function by calling the Transition.step_out
method:
>>> after_ret_tr = rep_tr.step_out()
>>> print(after_ret_tr)
#49582 mov eax, dword ptr [rbx+0x10]
>>> call_tr = rep_tr.step_out(is_forward=False)
>>> print(call_tr)
#49574 call qword ptr [rip+0x4af2]
This is useful in particular to, for instance, get to a transition where the return value of the function is available, or get to a transition where the parameters of the function are available:
>>> # Find the first parameter and the return value from any transition.
>>> #
>>> # Note: this assumes standard Windows 64-bit calling conventions, and that the there is one pointer-sized argument and
>>> # one pointer-sized return value. For more precise signature recovery, see reven2-ltrace.
>>> def print_first_parameter_and_return_value(tr: reven2.trace.Transition) -> None:
>>> loc = tr.context_before().ossi.location()
>>> if loc is None:
>>> loc = "???"
>>> first_tr = tr.step_out(is_forward=False)
>>> if first_tr is None:
>>> first_param = "???"
>>> else:
>>> first_param = hex(first_tr.context_before().read(reven2.arch.x64.rcx))
>>> last_tr = tr.step_out()
>>> if last_tr is None:
>>> ret = "???"
>>> else:
>>> ret = hex(last_tr.context_before().read(reven2.arch.x64.rax))
>>> print(f"{loc}: first_param={first_param}, ret={ret}")
>>>
>>> print_first_parameter_and_return_value(rep_tr)
ataport!AtaPortWritePortBufferUshort+0xe: first_param=0x170, ret=0xffffd001e7721558
Similarly, the Transition.step_over method can be used to skip a function on a call or ret instruction:
>>> call_tr.step_over() == after_ret_tr
True
>>> after_ret_tr.step_over(is_forward=False) == call_tr
True
Using the backtrace
For any context, you can get the associated call stack by calling the Context.stack property:
>>> # Getting the call stack
>>> rep_ctx = rep_tr.context_before()
>>> stack = rep_ctx.stack
>>> stack
Stack(Context=49579)
>>> # Displaying a human-readable backtrace
>>> print(stack)
[0] - #49574 - ataport!AtaPortWritePortBufferUshort
[1] - #49409 - atapi+0x23b0
[2] - #49392 - ataport!AtaPortGetParentBusType+0x3ef0
[3] - #49367 - ataport+0x6164
[4] - #49347 - ataport!AtaPortInitialize+0x49e0
[5] - #49323 - ntoskrnl!KeSynchronizeExecution
[6] - #49064 - ataport!AtaPortGetParentBusType+0x3ef0
[7] - #49000 - ataport!AtaPortInitialize+0x45a0
[8] - #48910 - ataport!AtaPortInitialize+0x3370
[9] - #48662 - ataport!AtaPortInitialize+0x2fac
[10] - #48097 - wdf01000+0x368e0
[11] - #47666 - wdf01000+0x19a70
[12] - #47597 - cdrom+0x5e30
[13] - #47529 - cdrom+0x1000
[14] - #46015 - wdf01000+0x368e0
[15] - #45936 - wdf01000+0x23ff8
[16] - #45927 - wdf01000+0x24d60
[17] - #45894 - ntoskrnl!IopProcessWorkItem
[18] - ??? - ntoskrnl!ExpWorkerThread+0x80
From there, you can use the backtrace to navigate in at least two ways:
- By going back to the caller of the current frame.
>>> # Finding back the caller transition if it exists
>>> print(next(stack.frames()).creation_transition)
#49574 call qword ptr [rip + 0x4af2]
- By going back to the previous stack. This allows for instance to switch from kernel land to user land, or to find/skip syscalls when necessary.
>>> print(stack.prev_stack())
[0] - #45719 - ntoskrnl!SwapContext
[1] - #45695 - ntoskrnl!KiSwapContext
[2] - #45487 - ntoskrnl!KiSwapThread
[3] - #45431 - ntoskrnl!KiCommitThreadWait
[4] - #45248 - ntoskrnl!KeWaitForMultipleObjects
[5] - ??? - dxgkrnl!DxgkUnreferenceDxgResource+0x2576a
Feature overview
The following table offers a simple comparison between widgets and features of Axion and Python API methods:
| Widget | API |
|---|---|
| CPU | Context.read |
| Trace view | Transition, Context.ossi.location, Context.ossi.process |
| Hex dump | Context.read |
| Memory History | Trace.memory_accesses, Transition.memory_accesses |
| Search | Trace.search |
| Backtrace | Context.stack |
| String | Trace.strings |
| Taint | Available in preview: preview.taint |
Going further
This concludes the Python API quick start guide. For further information on the Python API, please refer to the following documents:
-
Python API analysis examples that are distributed in the
Downloadspage of the REVEN Project Manager. These scripts demonstrate the possibilities offered by the Python API through more elaborate examples. Their documentation is available here. -
IDA Python API examples that are distributed in the
Downloadspage of the REVEN Project Manager. These scripts showcase the IDA compatibility of the Python API, that is, the simple capability of using the Python API from IDA:>>> import reven2 # This works from IDA, too -
The full Python API reference documentation
Jupyter Integration
REVEN includes a Jupyter notebook server so that you can easily create notebooks on a given scenario from the Project Manager.
Jupyter notebook is a web interface that allows, among other things, to execute Python code and prepare Markdown write-ups from your browser.
Using Jupyter notebook
To start using Jupyter notebook, please follow the steps below:
-
From the
Analyzepage of any scenario, click theOpen Pythonbutton. -
In the newly opened browser tab, click the
NewbuttonNote: When creating a new Python notebook, always choose the current version of REVEN, e.g. for REVEN 2.5, choose
reven-2.5-python3, otherwise you will not be able toimport reven2successfully. -
Go back to your
Analyzetab and click theCopy to clipboardbutton to copy the snippet allowing you to connect to the REVEN server. -
Paste the snippet as the first cell of the notebook. Execute the snippet using for instance Shift+Enter.
Axion-Jupyter synchronization
Jupyter notebooks also benefit from the Python/Axion synchronization feature.
When using the Jupyter integration, transitions are displayed as clickable links. Clicking these links will instruct any synchronized Axion to go to that transition.
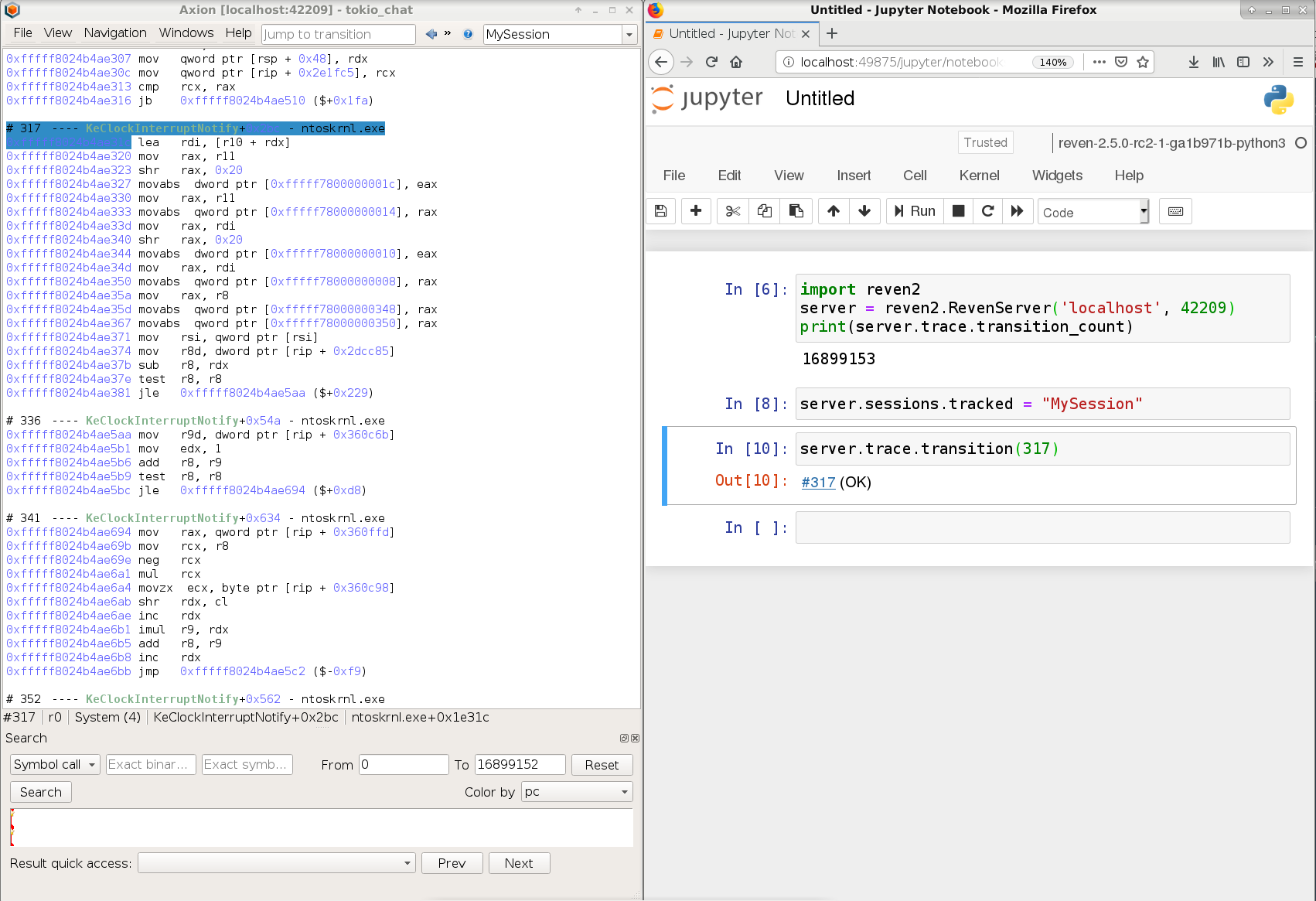
REVEN v2 - Cookbooks
NOTE: The automatic record feature is not available on the Professional Edition. This section only applies to the Enterprise Edition.
REVEN v2 - Auto-record on QEMU
NOTE: The automatic record feature is not available in the Professional Edition. This page only applies to the Enterprise Edition.
The auto-record feature in the Project Manager Python API allows you to perform a record without having you starting and stopping the record manually, detecting automatically when the record should start/stop instead. Also, when using the autorun feature, you will be able to completly bypass any manual interaction with the guest to perform the record.
Note that the auto-record functionality is currently in preview and exclusive to QEMU. As a result, it may contain bugs, and the interface is subject to change in a later version. In particular, the API we currently offer requires manipulating fairly low-level concepts.
This documents aims at explaining how to use the auto-record API. To do so, it covers the following topics:
- The general concepts of automatic recording required to use the API
- How to use autorun to allow a fully automated recording
- How to use the two auto-record types available in the API:
- Recording a single binary
- Recording using ASM stubs to allow precise control over when to start/stop the record from inside the guest.
You can find a complete example of using the auto-record feature in the Project Manager Python API examples named automatic-binary-record.py.
General
Concept
To perform auto-records, the Project Manager uses a recorder, which will communicate with the hypervisor in order to monitor the execution in the guest. So, the recorder knows what is happening on the guest, and is able to ask the Project Manager to start or stop the record after a specific event occurred. (e.g the start of a binary or a special sequence of ASM instructions executed by the guest).
The recorder requires initialization before it can enter the ready state, and this operation can take time depending of the state of the guest.
As a result, you will need to monitor the status of the recorder. You can retrieve the current status of the recorder from the field recorder_status of an auto-record task (retrieved by calling the get_task method of the Project Manager Python API)
Here is the list of possible statuses:
NOT_READY: Therecorderisn't ready and initialized yetREADY: Therecorderis ready, it will start the record as soon as the expected event occursRECORDING: The record has been startedRECORDED: The record has been stoppedFAILED: The auto-record failed for a specific reason (you can retrieve the reason in the fieldfail_reasonof a auto-record task)ABORTED: The record was aborted for a specific reason (you can retrieve the reason in the fieldfail_reasonof a auto-record task)TIMEOUT: The auto-record timed out before the start of any record (see the argumenttimeout_startin the next section)RECORD_TIMEOUT: The auto-record timed out during the record. The record was saved anyway. (see the argumenttimeout_recordin the next section)RECORD_COMPLETED: The auto-record succeeded and the record was saved
You should not assume that the recorder_status will only go from the RECORDING to the RECORDED status: you will encounter cases where the status will reach RECORDED at some point, and then go back to RECORDING. This may happen for instance when recording a binary because the recorder has detected that it may reduce the trace size without losing useful information, by stopping the current record and starting a new one. Similarly, code that uses the ASM stub is free to start and stop several records.
When the recorder is ready, the Project Manager will insert a CD-ROM into the guest containing the input files of the scenario and the mandatory file for the autorun.
Generic arguments
The auto-record feature is accessible via the Project Manager Python API via one method per auto-record type. All the methods use a set of common arguments described here:
qemu_session_id: The id of the session used during the auto-record (you can retrieve it in the JSON when using thestart_qemu_snapshot_sessionmethod from the Project Manager Python API to start a snapshot)scenario_id: The id of the scenario where the record will be saved, it should not already contain a record.timeout_start: The maximum number of seconds to wait between the point where the recorder is ready and the start of the record (default:300,0for infinite).timeout_record: The maximum number of seconds to wait when recording before stopping it (default:60,0for infinite).autorun_binary: See the next section.autorun_args: See the next section
Each of these methods returns a JSON object with a task key containing the representation of a task. With this data and the get_task method of the Project Manager Python API, you can pull the task's data repeatedly to know when the auto-record is finished, and get the recorder_status (a status listed in the previous section) (See the Project Manager Python API examples).
How to wait the end of the auto-record
from reven2.preview.project_manager import ProjectManager
# Connecting to the Project Manager with its URL.
project_manager = ProjectManager(url="https://user:password@url.to.project.manager:8880")
# Launching the auto-record and retrieving its task
auto_record_task = project_manager.auto_record_XXX(
# ...
)['task']
print("Launched auto-record task with id: %d" % auto_record_task['id'])
# Waiting for the end of the task
while not auto_record_task['finished']:
sleep(1)
# retrieve the task with updated information
auto_record_task = pm.get_task(auto_record_task['id'])
print("Recorder status: %s" % auto_record_task['display_recorder_status'])
print("Auto-record finished with status: %s" % auto_record_task['status'])
Autorun
When using either of the automatic recording methods, the Project Manager will allow you to automatically launch a binary, script or command on the guest. This allows for a fully automated record without any interaction from the user.
Note that although autorun isn't mandatory by itself, if you don't use it you will have to interact manually with the guest, e.g. to launch the binary you want to record.
To enable autorun on the guest, you will have to configure your guest to automatically execute the script contained in a CD-ROM following some instructions.
To enable the autorun on the automatic record, you will have to use these arguments:
autorun_binary: The binary, script or command to autorun on the guest when launching the auto-record. This could be either a string or the id of a file that was already uploaded to the Project Manager. Note that this will be launched from a bat script on Windows, so any valid batch command will also work, the same applies to Linux with bash.autorun_args: The arguments to give to theautorun_binary
NOTE: When the autorun is enabled, all the content of the folder will be copied to C:\reven\ on Windows and /tmp/reven on Linux and executed from there.
Commiting the record to a scenario
The autorecord will generate a record the same way you can do it with start_record and stop_record and will also need to be saved in a scenario by using commit_record.
You can do something as follow:
# Auto record stuff...
# - `auto_record_task` contains the JSON of the task after the end of the auto record
# - `session` contains the JSON of the session
# - `scenario` contains the JSON of the scenario
pm.commit_record(session['id'], scenario['id'], record=auto_record_task['record_name'])
# Now you have a scenario with a record, you can replay it.
Examples
Launching a custom Windows script
project_manager.auto_record_XXX(
autorun_binary="my_script.bat",
autorun_args=[
"1",
"\"C:\\Program Files\"",
],
autorun_files=[
42, # Id of `my_script.bat`
]
# ...
)
This example will launch the script my_script.bat also embedded in the CD-ROM like the following:
"my_script.bat" 1 "C:\Program Files"
Warning: To access my_script.bat from the guest, you need to put its id in the autorun_files argument
Launching a binary already in the guest
project_manager.auto_record_XXX(
autorun_binary="C:\\Program Files\\VideoLAN\\VLC\\vlc.exe",
# ...
)
This example will launch the executable C:\Program Files\VideoLAN\VLC\vlc.exe that is already present on the guest
Prepare the autorun
Windows
To allow autorun on Windows, you need to:
- disable Windows Defender:
- As an Administrator, launch
gpedit.msc. - On newer version of Windows, navigate to "Local Computer Policy\Computer Configuration\Administrative Templates\Windows Components\Microsoft Defender Antivirus\Real-time Protection\Turn off real-time protection" and
set the
Enabledradio button. - On older version, navigate to "Local Computer Policy\Computer Configuration\Administrative
Templates\Windows Components\Windows Defender\Turn off Windows Defender" and
set the
Enabledradio button.
- As an Administrator, launch
- enable
AutoPlayin the control panel (Hardware and Sound>AutoPlay) by setting "Software and games" to "Install or run program from your media".
NOTE: If autorun does not work despite following the instructions of this section, check that the
ShellHardwareDetection service is running. If it is not, enable the service and reboot the virtual machine.
If AutoPlay is disabled on your guest, you can still use a bat script which must be already launched on the guest when you start the automatic recording.
@echo off
title Wait CDROM Windows
:Main
timeout 2 > NUL
dir D:\ 1>NUL 2>NUL || GOTO Main
D:\autorun.bat
Warning: This script assumes that the CD-ROM will be mounted in D:, if it's not the case on your guest you should change it accordingly
Linux
Linux doesn't have an AutoPlay feature like Windows, so you will have to use a script to reproduce this feature. Like in Windows, this script must be already launched on the guest when you start the automatic recording if you want to use autorun.
#!/usr/bin/env bash
MOUNT_PATH=/media/cdrom0
while ! mount ${MOUNT_PATH} &> /dev/null
do
sleep 0.3
done
source ${MOUNT_PATH}/autorun.sh
Warning: This script was tested on a Debian guest, it may require modification in order to work for other distributions
Binary recording

Requirements:
- The guest must be a Windows 10 x64
- The snapshot must be prepared
- The mandatory PDBs should be available through the symbol servers or available in the symbol store
- The guest should be booted
- If you want to use the autorun, it must be configured.
To record a specific binary from the start of it until it exits, crashs or BSOD, you have to use the auto_record_binary method of the Project Manager Python API.
When using this auto-record, the recorder will resolve and watch specific Windows symbols, such as CreateProcessInternalW that is used to spawn new processes.
This method will record at least from the CreateProcessInternalW function and try to reduce the record by re-starting it at some important points using heuristics. Generally the first instruction of your trace will be the first instruction of the binary (on the entry point), but for some binaries the trace might instead start at the CreateProcessInternalW.
To indicate which binary you want to record, this method takes an extra parameter called binary_name, which should contain either the full name of the binary with the extension (and optionally with some parts of its path) or the id of a file that was previously uploaded to the Project Manager.
Note that autorun_binary and binary_name are different, autorun_binary is used to automatically execute something on the guest but won't start the record by itself, binary_name is an indication of which binary should be recorded.
Examples
project_manager.auto_record_binary(
binary_name="my_binary.exe",
# ...
)
Will record C:\my_directory\my_binary.exe but not C:\my_directory\my_second_binary.exe.
project_manager.auto_record_binary(
binary_name="my_directory/my_binary.exe",
# ...
)
Will record C:\my_directory\my_binary.exe but not C:\my_second_directory\my_binary.exe.
project_manager.auto_record_binary(
binary_name="directory/my_binary.exe",
# ...
)
Won't record C:\my_directory\my_binary.exe nor C:\my_second_directory\my_binary.exe.
Warning: Because the auto-record of a binary is based on the arguments of the function CreateProcessInternalW, you should provide a binary_name that is present in the command line used to launch it. See the next example.
project_manager.auto_record_binary(
binary_name="my_directory/my_binary.exe",
# ...
)
Here is some batch command lines to see when the record will be started and when not:
Rem This won't be recorded
cd my_directory
my_binary.exe
Rem This will be recorded
my_directory\my_binary.exe
Rem This won't be recorded
my_directory\my_binary
Rem This will be recorded
my_first_directory\my_directory\my_binary.exe
Rem This will be recorded
C:\my_first_directory\my_directory\my_binary.exe
If you want to use autorun to directly launch the binary instead of launching it yourself on the guest you can do something like the following:
project_manager.auto_record_binary(
autorun_binary="my_binary.exe",
binary_name="my_binary.exe",
# ...
)
Or using ids:
project_manager.auto_record_binary(
autorun_binary=5, # 5 is the id of the file "my_binary.exe" already uploaded to the Project Manager
binary_name=5,
# ...
)
Recording via ASM stubs
Requirements:
- If you want to use the autorun, it must be configured.
Automatic recording using ASM stubs allows you to directly control the record from the guest, e.g. to only record the execution of a specific function.
Using the ASM stubs described in the next section you are able to start, stop, etc the record automatically from within the VM. However, note that this ability comes with its own drawbacks, such as needing to modify a binary to insert the ASM stubs on the function you want to record.
NOTE: Auto-recording using ASM stubs should be OS agnostic, and was tested successfully on Windows 10 x64 and Debian Stretch amd64
ASM stubs
The ASM stub works by hijacking an instruction in the guest so that it is interpreted differently in the hypervisor when used with a specific CPU context. In REVEN v2, the ASM stub is the instruction int3 (bytecode 0xcc), when executed with a magic value in rcx.
So, when calling int3 you need to set these registers accordingly:
rcxto the magic value0xDECBDECBraxto the number id of the command you want to execute (see below)rbxto the argument to this command
The list of commands is:
0x0to start the record (if already started restart it). The argument must always be1for now.0x1to stop the record. No argument.0x2to save the record (save it and stop the auto-record here). The argument must always be1for now.0x3to abort the record. The argument is eitherNULLor a pointer to a NUL-terminated string containing the reason of the abort.
Examples
Recording a function execution
If you have an executable my_binary.exe with these sources:
void function_to_record() {
// ...
}
int main() {
// ...
// Start the record
__asm__ __volatile__("int3\n" : : "a"(0x0), "b"(1), "c"(0xDECBDECB));
function_to_record();
// Stop/commit the record
__asm__ __volatile__("int3\n" : : "a"(0x1), "c"(0xDECBDECB));
__asm__ __volatile__("int3\n" : : "a"(0x2), "b"(1), "c"(0xDECBDECB));
// ...
}
You can record it like the following:
project_manager.auto_record_asm_stub(
autorun_binary="my_binary.exe",
# ...
)
Recording two executables
If you want to record the execution of my_binary.exe and also my_second_binary.exe you can use something like the following.
With a binary start_record.exe:
int main() {
// Start the record
__asm__ __volatile__("int3\n" : : "a"(0x0), "b"(1), "c"(0xDECBDECB));
return 0;
}
With a binary stop_record.exe:
int main() {
// Stop/commit the record
__asm__ __volatile__("int3\n" : : "a"(0x1), "c"(0xDECBDECB));
__asm__ __volatile__("int3\n" : : "a"(0x2), "b"(1), "c"(0xDECBDECB));
return 0;
}
With a script my_script.bat:
@echo off
C:\reven\start_record.exe
C:\reven\my_binary.exe
C:\reven\my_second_binary.exe
C:\reven\stop_record.exe
You will be able to record them by uploading all these files into the Project Manager and calling auto_record_asm_stub like the following:
project_manager.auto_record_asm_stub(
autorun_binary="my_script.bat",
autorun_files=[
42, # Id of `my_script.bat`
43, # Id of `start_record.exe`
44, # Id of `stop_record.exe`
45, # Id of `my_binary.exe`
46, # Id of `my_second_binary.exe`
]
# ...
)
Mixing modes: binary recording + ASM stubs
The binary recording mode allows overriding its operations with ASM stub commands during the recording phase. This allows for more control in binary recording mode while still keeping the OS-related automation such as automatic recording stop on process stop or OS crash.
Binary recording mode automatically allows mixing ASM stubs, there is no option necessary to select.
Here is an example where the program will manually restart the recording even though the Binary recording mode had started it ealier:
In general, when mixing modes, ASM stub commands have priority over the binary recording heuristics while still allowing levegaring the binary automation:
- When the binary recording detects a start condition (process start):
- if the recording is already started, do nothing (do not restart it)
- if the recording has not started, start it
- When the binary recording detects a stop condition:
- if the recording is started, stop it
- if the recording is stopped, report an error
This mode makes it easier to record various situations, notably non-deterministic crashes: restarting a recording from within the program is easy, and the binary recorder will still catch the crash.
REVEN v2 - Auto-record on Vbox
NOTE: The automatic record feature is not available in the Professional Edition. This page only applies to the Enterprise Edition.
This document isn't as complete as the QEMU one, as the auto-record isn't a feature currently available for Virtualbox in the Project Manager Python API. However, this document will explain to you how to build your own auto-record on Vbox without any manual interaction with the guest.
This document covers the following topics:
- how to record in Vbox without using the keyboard shortcuts
- how to autorun your binaries in the guest.
Warning: This mode of operation is based on the way REVEN v1 was doing its auto-record, and is subject to change in a later version. Also note that this document won't talk about some advanced features of the auto-record using Vbox.
You can find a complete example of auto-record in Virtualbox in the Project Manager Python API examples called vbox-automatic-record.py.
ASM stubs
REVEN v1 has been using an hijacked instruction executed in the guest and interpreted differently in the hypervisor to control the record from the inside. This instruction is int3 with the magic value (0xDEADBABE) in rdx.
The commands are:
0xEFF1CAD6to start the record (when started you won't be able to restart it)0xEFF1CAD1to stop the record and stop the VM
Example
If you have a binary containing a function you want to record you can use ASM stubs:
void function_to_record() {
// ...
}
int main() {
// ...
// Start the record
unsigned ret;
__asm__ __volatile__("int3\n" : "=a"(ret) : "a"(0xEFF1CAD6), "d"(0xDEADBABE));
function_to_record();
// Stop the record and the VM
__asm__ __volatile__("int3\n" : : "a"(0xEFF1CAD1), "d"(0xDEADBABE));
// Can't reach this point, the previous ASM stub should have stopped the VM
__asm__ __volatile__("ud2");
}
All you have to do to record this function is to launch this binary in the guest and this will automatically start/stop the record.
Warning: The session should have been started in the step Record of the workflow of a scenario or from the Project Manager Python API using the method start_vbox_snapshot_session with the argument scenario containing the id of the scenario where you want to save your record.
Autorun
To enable autorun you will need to configure the guest in the same way as for QEMU autorun, and then follow the following instructions.
Windows
On Windows, AutoPlay (if configured correctly) will use the file autorun.inf at the root of the CD-ROM to know what to execute.
For example:
[autorun]
open=autorun.bat
shell\open\Command=autorun.bat
This will execute autorun.bat when the CD-ROM will be inserted.
If autorun.bat contains something like that:
@echo off
D:\my_binary.exe
With my_binary.exe containing the ASM stubs responsible for the start/stop of the record. You will just need to insert a CD-ROM into the guest containing autorun.inf, autorun.bat and my_binary.exe to auto-record what you want to record.
Linux
As Linux doesn't have the AutoPlay feature, you should have configured it to use a script which will execute automatically autorun.sh when the CD-ROM is mounted.
So, if autorun.sh contains something like that:
./my_binary
with my_binary containing the ASM stubs responsible for the start/stop of the record, you will just need to insert a CD-ROM into the guest containing autorun.sh and my_binary.exe to perform the auto-record.
Advanced usage
REVEN v1 used what we called preloaders that were responsible for starting the record at the start of the binary by using various methods:
- On Linux: using the
ptraceAPI to single step until the entry point is found - On Linux: using a
.sodynamically loaded withLD_PRELOADsetting a breakpoint at the entry point - On Windows: using the Windows API to start a suspended process and patch it
You can reproduce some of these methods using the ASM stubs explained in this document but the accuracy will probably not be sufficient to have the first instruction of the record be the first instruction of the binary.
RvnKdBridge
This program allows you to connect WinDbg (aka KD) to a REVEN server. When doing so, the REVEN trace will appear as a live, running system to the WinDbg client. This way you get the best of both worlds:
- High level semantic information and navigation with WinDbg.
- Timeless availability of your scenario along with all features of REVEN available through its API and its GUI.
Requirements on the REVEN scenario
For the WinDbg integration to work, your trace must have full OS Specific Information (OSSI).
Note that it is not required to start the VM with /debug when preparing it for recording.
Installation
You can find RvnKdBridge in the DOWNLOADS section of the Project Manager. Extract it anywhere your user can write a file.
Usage instructions
You will use RvnKdBridge in order to connect WinDbg to a REVEN trace. This program is intended to run on Windows alongside your WinDbg client: you will connect it to the REVEN trace, and it will create a named pipe WinDbg can connect to. This is similar to debugging a VM's kernel.
Here is how the programs connect together, with example values for the connection parameters:
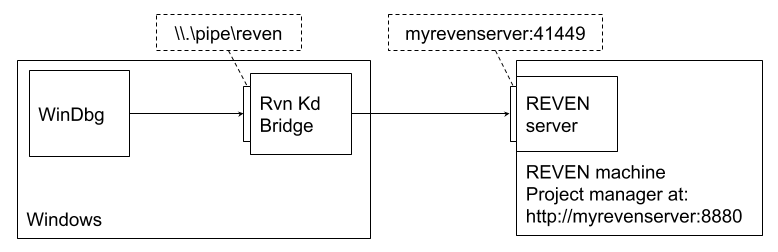
Make sure that your network configuration allows you to connect to the REVEN trace.
Starting the bridge
Launch the program RvnKdBridge.exe. There are multiple fields to fill in.
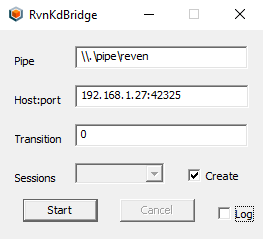
Pipe: Path of the named pipe to create. The format is\\.pipe\<mypipename>, for example\\.pipe\reven.Host:port: Description of the project's server & port. The format is<hostname>:<port>.- The host is the address of your server
- To find the port, you can go to the Analyze page for the scenario you want to connect with, and the port number will be displayed in the label above the buttons (
REVEN running on port xxxx):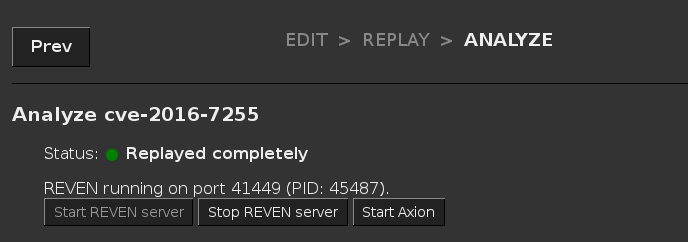
Transition: At which transition in the trace the bridge will start. WinDbg will see the REVEN trace as a VM stopped at this point in time for debugging.Createcheckbox: Whether or not a new synchronization session for Axion should be created.
Connecting WinDbg
The next step is to connect WinDbg to the named pipe you specified. The procedure differs slightly between WinDbg x64 and WinDbg Preview.
In WinDbg x64, follow the steps below:
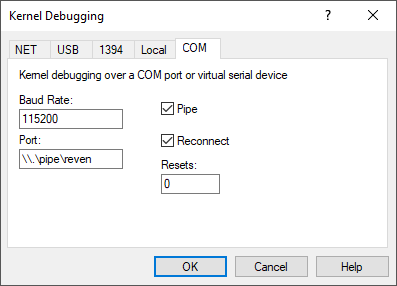
- Click on
File - then
Kernel Debug. - Select the
COMtab, - Check
Pipe. - In the
Porttext field, enter the name of the pipe. - Finally, click on
OK.
In WinDbg Preview, follow the steps below:
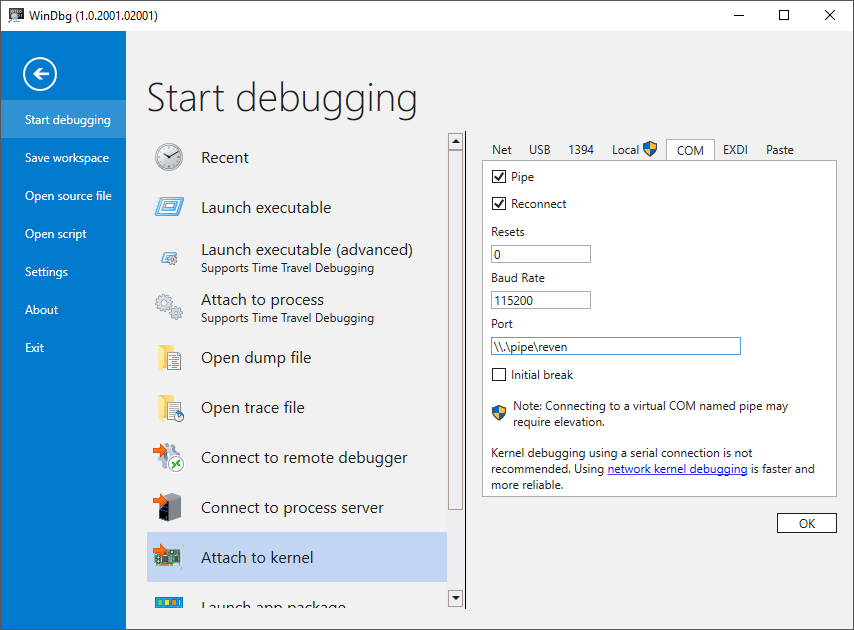
- Click on
File Start debugging- then
Attach to kernel. - Select the
COMtab, - Check
Pipe. - In the
Porttext field, enter the name of the pipe. - Finally, click on
OK.
Using WinDbg on a REVEN trace
You can now use WinDbg as if you were connected to a live running VM in kernel mode.
Reading the state
Most commands that read the current state of the debuggee will work. For example:
.reloadis necessary, thenlmk,dt.tlist,!peb,!handle,!time- Reading memory, especially reading structured data
- etc.
Note that when debugging at the start of a trace, some commands (callstack or !peb for example) may return unexpected results. This appears to be due to the state at the start of the trace (exception handling in the system process).
Browsing the trace
- You can use basic WinDbg tracing and stepping commands to
move in the trace. For simple commands, like
t, WinDbg will go automatically to the next transition. More complex commands might refer to events outside the trace, such as stepping out (gu) of a function that never returns. In such cases, the bridge will ask the user to enter the desired target transition. - You can set breakpoints using the
usual breakpoint commands. The
resumecommand (g) can then be used to jump to the next transition where a breakpoint is hit. If none of the breakpoints are hit in the trace after the current transition, then the bridge will ask the user to enter the desired target transition. In particular, if there are no breakpoint enabled, thengwill always allow to jump to a transition manually.
Synchronization with Axion
Once connected to the REVEN server, you can use the Sessions combo box to select a session name.
You can then select the same session name in an Axion GUI client connected to the same REVEN server,
in order to synchronize the Axion GUI with WinDbg.
This way, each time a new transition is selected in WinDbg (for instance using commands to browse the trace), the same
transition will also be selected in Axion.
If you checked the Create checkbox next to the Sessions combo box, then a fresh session name will be generated
by the bridge upon connecting to the server.
Current known limitations/issues
The following commands are currently not supported by the bridge:
- reverse step in / into / out
Moreover, commands that would end up writing to the debugged system do not make sense in the context of REVEN, since we're working on a read-only trace. Hence, the following commands are not supported:
- changing registers
- writing to memory
- any command that would result in a write to the debuggee's state, such as changing process via
.process /i
Troubleshooting
Here are answers to common errors you might encounter when using RvnKdBridge.
Bridge cannot connect to the trace
First, double-check that you are providing the right address and port. Note that the port is reported when starting a REVEN server, in the Analyze section under the Project Manager's Scenario tab.
Then, make sure your network setup allows communication between your Windows machine and the REVEN server.
WinDbg cannot connect to bridge
If WinDbg shows the error Kernel debugger failed initialization, Win32 error 0n1, make sure you did check Pipe while configuring the named pipe.
You may also get spurious errors such as Kernel debugger failed initialization, Win32 error 0n231 "All pipe instances are busy." - WinDbg might still be connected. You can ignore this error.
Bridge can connect to trace, but fails to recognize kernel
RvnKdBridge has been tested on various kernels and traces, ranging from Windows 7 up to Windows 10 RS6. Still, you might encounter conditions where the bridge may not work: required memory areas are unexpectedly not mapped, or the kernel is not supported.
The logs window might help you troubleshoot the problem.
If you find a kernel and/or a trace on which the bridge does not work, please try the following actions on the VM you recorded the scenario on:
- Deactivate the pagination file
- Reboot the VM
- Once fully rebooted, record a new, small trace and try to connect the bridge again.
If these actions do not help, please contact the support by copying the logs, details about the scenario such as kernel version, or ideally a very small scenario displaying the problem.
REVEN Python API installation guide
Prerequisites
The supported platforms for installing the REVEN Python API are Debian 10 Buster 64 bits and Windows 10 64 bits. A working 3.7 (CPython) installation is also required.
Note for Debian: other dependencies will be installed over the course of this document and can be found in the
dependencies.sh file.
Python 2 / Python 3
Since Python 2 reached its end-of-life in January 2020, we only provide a Python 3 version of the API.
Via Jupyter Notebook
REVEN provides integration with Jupyter Notebook, which allows you to use the REVEN Python API from your browser. For more information on this method of using the API, please refer to the dedicated documentation page.
On the REVEN server
If your Python development environment is on the same machine as your REVEN server, then the Python API is already
installed, and you just need to activate it.
Go to the install path of your REVEN package, then execute the following in a bash shell:
source sourceme_python3
This results in activating a virtualenv with the Python API installed. To
deactivate it and get back to your original Python environment, either open a new shell, or run the deactivate
command in the current shell where the virtualenv was activated.
Note that the sourceme_python3 file is a bash script and may not work as intended when
sourced from different shells (fish, zsh...).
On a client workstation
To install on a client workstation, you will need to download the corresponding archive from the Download
page of the Project Manager.
Choose the package corresponding to the desired OS and Python version.
This section assumes that you are working from the root directory of the decompressed archive.
Virtualenv / user-wide / system-wide
Python development provides many ways of installing a Python package. This document covers the main installation options.
-
Using a virtualenv: A local installation that won't conflict with any other Python environment in your system. This is the most recommended way to make Python development, since it will guarantee that you won't break any existing Python script by accidentally upgrading a common dependency.
On Debian 10 Buster, we provide asourcemebash script that automatically creates a virtualenv containing the REVEN Python API for you. For a virtualenv installation under Windows, you will first need to activate a virtualenv and then usepipnormally during the next section. -
A user-wide installation: This installation does not conflict with other users on the system, but you may have to manually setup the environment for your Python packages to be found.
For a user-wide installation, you'll need to usepipwith a--useroption after theinstallargument during the next section. -
A system-wide installation: This installation may conflict with other users or applications on the system, and requires root privileges. But after a system-wide installation, any user on the system will be able to use the REVEN Python API.
For a system-wide installation, you will need to usepipwithrootprivilege on Debian Buster (sudofor example), and normally on Windows during the next section.
Windows
First, be sure to have a 64-bit 3.7 installation available with the pip utility installed. The default Python
installer typically provides this component.
NOTE: the REVEN python API is not compatible with a 32-bit python environment.
- Step 1 (optional): create the virtualenv
The following Powershell lines will provide you with a virtualenv namedenvin your current working directory.
python.exe -m pip install virtualenv # Not required if you already have virtualenv installed
python.exe -m virtualenv --system-site-packages env
env\Scripts\activate
- Step 2 (required): upgrade the
piputility:
python.exe -m pip install --upgrade pip
- Step 3 (required): install the REVEN API
Paths are given relative to this current folder.
python.exe -m pip install (Get-Item dependencies\*.whl).FullName
python.exe -m pip install (Get-Item reven_api*.whl).FullName
python.exe -m pip install (Get-Item reven2*.whl).FullName
Debian 10 Buster
For a Debian 10 Buster client, the recommended way to use the Python API is to simply source the sourceme file
contained in the downloaded archive:
- Step 1 (required): install the system dependencies
Paths are given relative to this current folder.
sudo ./dependencies.sh
- Step 2: source the
sourcemefile
source sourceme
This will leave in a virtual environment where reven2 can be imported:
python -c "import reven2"
Note that the sourceme file is a bash script and may not work as intended when
sourced from different shells (fish, zsh...).
Debian 10 Buster, manual installation
If you prefer installing in your own virtualenv, or as user or system-wide, follow the instructions below.
First, be sure to have a Python installation available with the corresponding pip utility installed.
- Step 1 (required): install the system dependencies Paths are given relative to this current folder.
sudo ./dependencies.sh
- Step 2 (optional): create the virtualenv
sudo apt install python3-venv # If venv is not already installed
python3 -m venv --system-site-packages env
source env/bin/activate
- Step 3 (required): upgrade the
piputility
python -m pip install --upgrade pip
- Step 4 (required): install the REVEN API
Paths are given relative to this current folder.
python -m pip install dependencies/*.whl
python -m pip install reven_api*.whl
python -m pip install reven2*.whl
Next steps
If you successfully completed the previous steps, you should have a working REVEN Python API. Feel free to check out the Quickstart guide for a smooth kick-off.
Replay stage: Features & Resources
After recording a scenario, you will need to replay it in order to generate data required by the features you will use during the analysis stage.
In the replay stage, you are presented with a list of available REVEN's features. Resources data needed for each feature are discoverable by clicking on the feature row. In some features, there are also actions available.
By default, the Trace and Framebuffer features are selected.
NOTE: Axion cannot be launched if no trace data is available.
Features, Resources and Actions
Features match actual features available in Axion. For example, in order to visualize the Framebuffer in the Axion GUI, you will need to replay the Framebuffer feature during the replay stage.
Resources refer to the file(s) and data generated during the replay of a feature
in the replay stage. For example, the Backtrace feature replay output comprises
the "Stack Events" resource. Stack events regroup every data needed to display
the backtrace in Axion.
Actions are steps related to a feature that do not produce a resource. As such, these actions can be repeated.
For example, a current action is the Download light PDBs action, that allows to download external PDB. It can be useful to repeat this action if the symserver changes (e.g., contains new PDBs).
As such, an action is not necessarily mandatory to use a feature, but may improve the completeness of the feature (e.g., having more PDBs allows to resolve more symbols).
Available features and associated resources
The features present in the replay stage of the Project Manager are listed below:
| Feature | Resource(s) | Dependencies | Description |
|---|---|---|---|
| Trace | Trace |
| Contains all the transitions occurring during a scenario. |
| Framebuffer | Metadata |
| Allows displaying the framebuffer for any transition in a scenario in Axion. |
| OSSI | Light Filesystem & Kernel Description |
| Contains all the information to retrieve the OS-specific information in the Trace. |
| Memory History | Memory History |
| Contains every read and write memory access in a Trace. |
| Strings | Strings |
| Contains strings dynamically built during a scenario. |
| Backtrace | Stack Events |
| Contains the active stack frames for any transition in a Trace. |
| Fast search | OSSI ranges & PC ranges |
| Provides indexes to speed up the Search feature. |
| Filters | OSSI ranges |
| Provides indexes to filter the trace. |
NOTE: Some features can be immutable. This means they cannot be generated or deleted (without deleting the scenario).
For example, in a Snapshot-less scenario (e.g: imported scenario), the light filesystem resource is immutable, as we wouldn't be able to regenerate it, since light filesystem generation requires a snapshot.
Resources & Features statuses
Features and Resources can have the following statuses:
: Compatible, means the resource is up-to-date and can be used with the current REVEN version.
: Ready, means the resource is not versioned then can be used with the current REVEN version.
: Compatible but generated with a different REVEN version, means the resource is not up-to-date but can still be used with the current REVEN version. To make the resource up-to-date, you need to replay it, doing so you will benefit from bug fixes and minor updates.
: Not compatible, means the resource is not compatible with the current REVEN version because of a breaking change. The current REVEN server will not be able to read it. You will need to re-generate the resource to make the associated feature available again.
: Replay failed, means the resource is not available because a problem occurred during the replay. Please consult the replay logs and/or try to replay the resource again.
: Replaying, means the resource is being generated.
: Pending, means the resource generation is waiting for some system resources or a dependent data resource to be available.
: Not generated, means the resource is not generated yet.
: Deprecated, means the resource is deprecated and won't be used by REVEN anymore. You can delete it.
Actions statuses
Actions can have the following statuses:
: Success, means the action was ran successfuly once and could be re-run.
: Failure, means the action encountered a problem during the execution. Please consult the replay logs and/or try to replay the action again.
: Running, means the action is being executed.
: Pending, means the action is waiting for some system resources or a dependent data resource to be available.
: Not ran, means the action wasn't ran at all.